
DDD, Microservices, and Evolutionary Architectures: Why You Shouldn’t Share Domain Events
In the previous articles of this series on Domain-Driven Design, we explored the benefits of breaking down an architecture into modules—not necessarily microservices—, evolutionary architectures, and the importance of strategic patterns such as Bounded Context and Ubiquitous Language.
In this article, I’ll walk you through another key class of patterns discussed by Eric Evans in his well-known book ““: the tactical patterns — and some important precautions when working with Domain Events.
Designing for Evolution
The first step toward building an evolutionary architecture is designing software that can easily adapt to change. It sounds simple, but in practice, it’s anything but straightforward.
What does it mean to build a system that evolves continuously, following the Client’s needs? Let’s start with a common scenario: legacy code. This term is often associated with outdated applications that need to be rewritten using modern technologies. But that view is too narrow. Code can be considered legacy even if it was written just last week.
What makes code legacy is how hard it is to modify. The application generates value for the business, but every maintenance or enhancement effort carries risks. Strong internal dependencies between objects make the system fragile: changing one part might force a full review of the entire project. It’s no surprise that this slows down any improvement initiatives.
Domain-Driven Design offers practical support. To improve maintainability, the best strategy is to split the application into small, cohesive modules. You don’t have to go all the way to microservices, but each module should be tied to a specific business area.
Strategic patterns like Ubiquitous Language and Bounded Context are extremely valuable in this regard. Still, they’re not enough. A Bounded Context can still cover a wide slice of the business domain. That means the risk of managing overly complex components remains.
That’s why E. Evans also introduced a set of tactical patterns, designed to support the actual implementation of software. We won’t cover them all — they’re detailed in his book — but we’ll explore those that help build software that is durable, stable, and easy to maintain.
Aggregate
Among the tactical patterns in Domain-Driven Design, the Aggregate is one of the most important. It represents a simplified version of the business model we want to implement. It’s a central and multifaceted pattern. An Aggregate is made up of one or more Entities and one or more Value Objects.
At first glance, it might seem easy to design. In reality, correctly defining an Aggregate is one of the most complex tasks in software development. Since it is a simplified representation of the business model, it must remain as faithful as possible to the real-world processes it describes.
Without diving too deep into theory, software can solve business problems as long as the implemented model closely reflects the real one. Ideally, each new client request should be doable without needing to force or break the existing structure.
But does this bring us back to square one? Not at all. An Aggregate is not just a container of data. It must also expose methods that define its behavior. All logic related to the problem it addresses goes through it—and only through it.
This approach offers a significant benefit: changes to domain behavior affect only the specific Aggregate involved. They don’t cascade across the entire application. Each Aggregate is a self-contained unit. It communicates with others, yes, but it makes decisions independently, enforcing its own business rules—its invariants.
Internal Communication Within the Aggregate
To maintain the isolation of internal objects in an aggregate, every interaction must go through a specific entity: the Aggregate Root (or Entity Root).
A classic example is a sales order composed of a header and multiple line items. You cannot modify the line items directly. All operations must go through the order header, which acts as the Aggregate Root. This entity is responsible for invoking the appropriate methods on the line items and coordinating any changes.
Once the operation is complete, the Aggregate Root must also validate that the business rules—its invariants—are respected. For example, it should ensure that the updated order total does not exceed the customer’s available budget.
Improving Maintainability and Data Consistency
Centralizing behavior in a single part of the code is a strategic choice that improves maintainability. By narrowing the aggregate’s scope, we reduce complexity while preserving clarity and consistency with the business problem being addressed.
And what about data consistency? Since the Aggregate Root checks all business rules after every state change, it ensures consistent data within the system. This is not a secondary concern: an aggregate must be consistent from the moment it is created.
From a technical perspective, an aggregate should never be created using a factory without parameters. In a well-modeled domain, this practice is unacceptable. And this is precisely where the first real challenges in sizing Aggregates correctly begin.
Sizing the Aggregate
An aggregate that’s too large introduces increased complexity and greater contention. It’s more likely that multiple requests will target the same aggregate. As a result, it must handle many invariants and business rules, which makes the code harder to maintain.
What’s the upside? In terms of consistency, the model becomes more robust. A wider scope ensures that a larger amount of data remains consistent with every state change.
On the other hand, a smaller aggregate reduces data consistency but offers simplicity and better concurrency management.
Here’s a practical example. Imagine a booking system for a multiplex cinema. If the aggregate represents the full day’s schedule, you gain a high level of consistency. All details—movies, screens, times, available seats—are part of a single context. However, the aggregate must handle high contention.
If instead you model the aggregate as a single screen, the system becomes simpler. It only has to manage seat bookings for one show. Could we go further? Yes—we could make a row the unit of aggregation.
Which option is best? It depends on the context. While there’s no such thing as an “aggregate that’s too small” in absolute terms, overly fine-grained models can add unnecessary design overhead. The right balance should always reflect the domain and real-world requirements.
Domain Event
Now that we have seen how to isolate domain behaviors to make applications more maintainable, a natural question arises: how can different aggregates communicate with each other?
If the aggregates belong to the same Bounded Context, the solution is relatively simple. Each aggregate has its own Aggregate Root responsible for managing interactions with the outside. In these cases, a Domain Service can effectively orchestrate the communication.
Things get more complex when it is necessary to notify a state change to an aggregate located outside its own Bounded Context. In these scenarios, a fundamental pattern comes into play: the Domain Event.
But what exactly is a Domain Event? A Domain Event has two essential characteristics:
- It describes something that has already happened. For this reason, its name should always be expressed in the past participle (e.g., “OrderCreated,” “PaymentReceived”).
- It is immutable. It cannot be changed in any way because it represents an event that occurred in the past. At most, it can be compensated by a subsequent action.
Domain Events belong to the domain model. They are not generic notifications and should not be distributed indiscriminately. A useful criterion to determine if it is a true domain event is to ask: “Does this event matter to the domain experts?” If the answer is yes, then it is a Domain Event.
At this point, we might wonder: why don’t Domain Events appear in Evans’s book? There is no definitive answer. However, it’s clear that this pattern gained more relevance with the shift toward distributed architectures. In a distributed context, where components must be loosely coupled, message exchange becomes a natural solution.
The success of Domain Events is closely tied to the rise of microservices and the adoption of event-driven architecture. Not surprisingly, when discussing events in Domain-Driven Design, the immediate reference is the CQRS+ES pattern (Command Query Responsibility Segregation + Event Sourcing) introduced by Greg Young.
CQRS
CQRS (Command Query Responsibility Segregation) is the evolution of the CQS (Command Query Separation) pattern by Bertrand Meyer, the creator of the Eiffel language and one of the pioneers of OOP. He theorized a clear separation between an action that modifies the data inside the database (Command) and one that reads the data present in the database (Query).
The first is allowed to change the state of a record but does not necessarily have to return a result, except whether the operation succeeded or failed. The second must never modify data but only return the data matching the query. If no changes occur, the query must always return the same result (idempotent).
Greg Young’s innovation was to separate the database into two distinct parts: one for writing and one for reading data. The main idea is that if a database is optimized for writing, it will not be optimal for reading, and vice versa. As often happens, a picture is worth a thousand words.
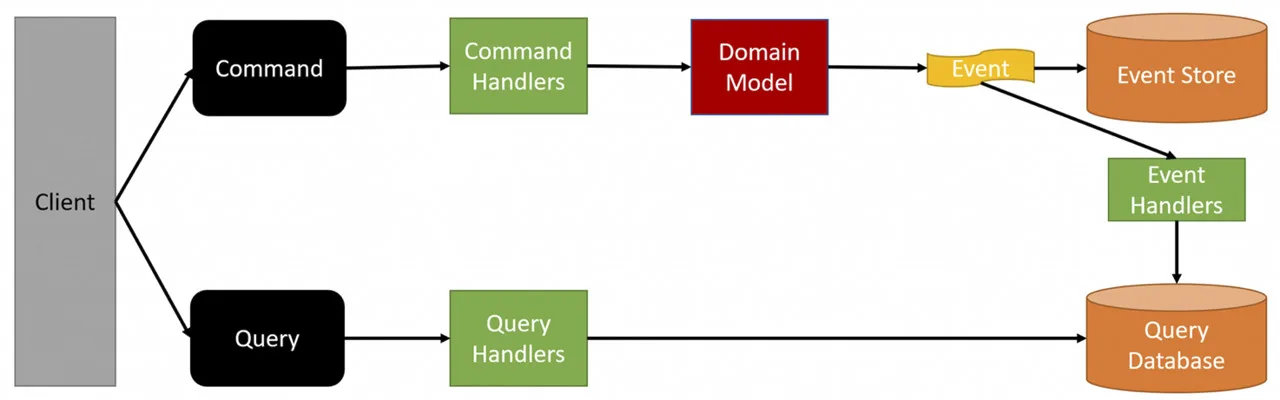
To fully understand how the pattern works, let’s analyze the steps shown in the figure:
- The Client sends a Command to request a state change on an Aggregate. An example could be: CreatePurchaseOrderFromPortal. It is crucial that the command name clearly describes the business intent it represents.
- The Command is handled by a Command Handler. This component executes the methods defined within the Domain Model, that is, the Aggregate. Remember, the Domain Model should not only represent data but also include the business logic needed to manage state changes.
- The Aggregate evaluates the received command. If the requested action violates a business rule (for example, exceeding the customer’s budget), the operation is rejected. After processing, the Aggregate emits a Domain Event representing the event that just occurred. In asynchronous systems, it is good practice to emit events even on failure, allowing the UI or other components to react properly.
- The Domain Event is stored in the Event Store. This step is essential if using Event Sourcing: storing events is the only way to rebuild the Aggregate’s state from its history. It is possible to use the same database for both the Event Store and the Read Model if you want to keep the architecture simple.
- The event is then published. Any component or service within the same Bounded Context that wants to react to the change can subscribe and update its own Read Model accordingly.
- Queries from the Client do not interact with the Aggregate but rely exclusively on the Read Model, which can be structured with various projections to support specific UI needs.
Domain Event
The Domain Event is an integral part of the domain model: it represents a fact that has already occurred within the application domain. Instead of simply storing the current state of an aggregate, each state change is recorded as a domain event.
Every time a new command is applied — or rejected because it violates a business rule — the aggregate is rebuilt by replaying all the associated Domain Events in sequence. This process produces an updated and consistent projection of the object.
This approach shifts the perspective: it moves from a “snapshot” of the current state to a “movie” that shows how the aggregate reached its current configuration.
As mentioned earlier, Domain Events are always expressed in the past tense because they describe something that has already happened. No system component can question their validity: these are established facts.
This approach offers significant flexibility. Business logic stays confined within the Aggregate, preventing its spread across multiple layers or services. This makes the system more stable and easier to maintain. When introducing changes or adding behavior, you only need to ensure tests continue to pass. This guarantees nothing outside your Bounded Context is broken.
Finally, anyone subscribing to a Domain Event must treat it as immutable and definitive data. No conditional logic should be applied to the received event; it is assumed to represent a historical truth.
How Is a Domain Event Structured?
A Domain Event is, in every respect, a Data Transfer Object (DTO). It contains information about the changes that occurred within the aggregate. In practice, this means it only exposes the properties that changed as a result of executing a command.
A concrete example of an implementation in C# is shown in the following figure.
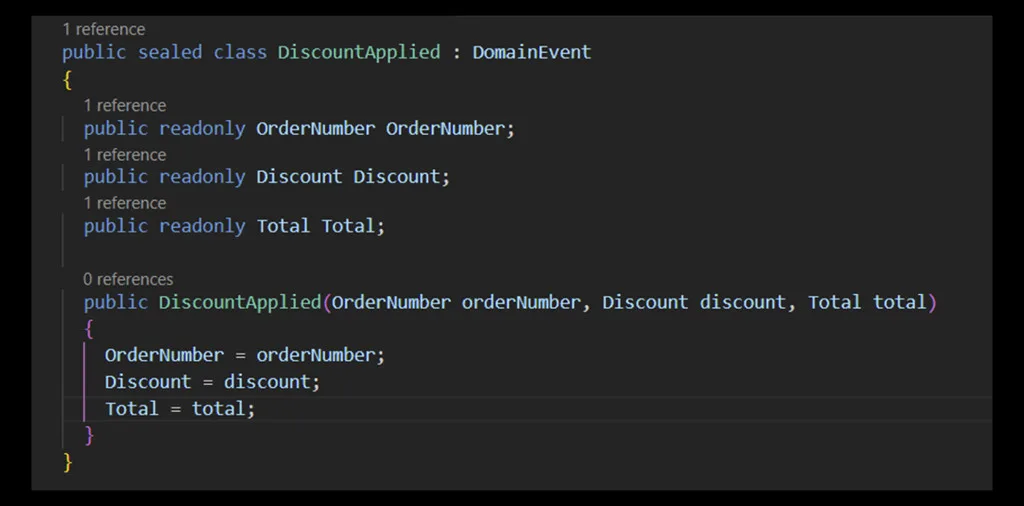
Let’s start by analyzing the code of the Domain Event. The class is sealed, meaning it cannot be inherited or extended within the code. This choice ensures the behavior of the Domain Event remains unchanged.
All properties of the class are readonly. This design has a clear purpose: our Domain Event must be serialized before being sent and deserialized upon reception. During these operations, no modification of data is allowed to guarantee that the content remains intact and unaltered. In other words, what leaves the domain must arrive at the recipient without changes.
Another important aspect concerns the semantics used within the Domain Event. Instead of using primitive types, custom types are employed, consistent with the business language, i.e., the Ubiquitous Language. For example, if a primitive type like string or UUID were used to represent the order number, only technical staff could interpret it correctly. By contrast, using a custom type like Order Number removes communication barriers between the technical team and the business team. This greatly reduces the risk of misunderstandings and errors in producing code that does not meet specifications.
Modeling the Aggregate in Relation to Reality
When modeling an Aggregate—that is, the business model we aim to solve—it is crucial to remain as faithful as possible to reality. As previously emphasized, having a common language among team members is essential. Naturally, we will need to simplify certain concepts because fully replicating a real-world model within our code is not feasible.
To prevent our model from diverging too much from reality, it is important to create aggregates that are as small as possible, striving to stay as close as possible to the concrete situation. It’s similar to considering a complex business process as a geometric shape, whose surface we cannot calculate precisely unless we divide it into multiple parts that we then integrate to obtain a final result. Although not perfect, this result will be very close to reality.
This approach allows us to simplify and solve the problem without losing too much in terms of realism.
Finally, every Domain Event must include the ID of the aggregate it belongs to, and, if applicable, the ID of related operations. Since these properties are repeated in every Domain Event, it is advisable to group them into a DomainEvent class. This not only simplifies the writing of Domain Events but also makes it immediately clear, by looking at the code, whether the object in question represents a Domain Event.
Who Can Subscribe to a Domain Event?
At this point, it is essential to ask which parties are interested in subscribing to a Domain Event and who is legitimately allowed to do so. Since a Domain Event intrinsically belongs to the domain, it cannot and must not leave our Bounded Context!
As seen in the image related to the CQRS/ES pattern, the Domain Event serves to update our Read Model—the data subset that users of our application query to make decisions. In a distributed system, this information may be duplicated and replicated across various Read Models, each belonging to different Bounded Contexts and potentially different microservices, i.e., on separate databases.
But how do we keep all these Read Models, which lie outside our Bounded Context, up to date? The lazy developer’s answer might be: “The Domain Event.” However, if not managed properly, the system risks quickly turning from distributed into a kind of “Big Ball of Mud”—a disorganized and hard-to-maintain system.
![Schema del Domain Event (da Vernon [1])](https://www.intre.it/wp-content/uploads/architettureevolutive-5_3.webp)
However, the issue goes beyond semantics—it’s also about implementation. As discussed in part 4 of this series, regarding Evolutionary Architectures, sharing components between codebases creates coupling. This limits the ability of individual parts to evolve independently. Each change risks affecting the others.
Aggregates are simplified representations of business problems. Since business challenges are human-centric and constantly evolving, aggregates will eventually become outdated. This isn’t a design flaw or premature optimization—it’s natural. Things change. This aligns with Taleb’s concept of antifragility, previously explored in the context of evolutionary systems.
The real goal is not to build a perfect system, but one that can adapt. Sharing a Domain Event conflicts with this philosophy. It prevents Bounded Contexts from evolving independently.
More than a semantic mistake, this is an architectural flaw. If the same contract is used to both maintain internal consistency between the Domain Model and the Read Model, and to communicate across Bounded Contexts, we face a constraint. We can’t change the aggregate freely without also changing the external contract.
Altering this contract means notifying other contexts and synchronizing deployments. In a microservices architecture, this would require republishing the shared Domain Event and updating all dependent services simultaneously. Otherwise, communication may break due to schema mismatches.
Ultimately, this leads to the worst of both worlds: distributed system complexity combined with tightly coupled monolith limitations. The result? A perfect Big Ball of Mud.
Integration Event
How do we notify the “rest of the world” that the state of our Bounded Context has been modified? We use an Integration Event. Technically, it is identical to a Domain Event, but it contains information that can be shared and is expressed in a language common to all Bounded Contexts in the system.
But what if the data in the Domain Event and the Integration Event are exactly the same? It doesn’t matter. We still publish an Integration Event. Sooner or later, the Domain Event is likely to change. When that happens, we can update the Domain Event without affecting communication with other contexts. The same Integration Event will continue to be published externally, ensuring that information flows without interruption.
This approach guarantees independence across different parts of the system. Each context can evolve freely without being tightly coupled to changes in others.
Versioning
What happens if, due to a new requirement, our Domain Event needs to change? For example, what if we need to add or remove a property?
First, it’s essential to determine whether the change alters the Domain Event’s meaning. If not, we can simply add new properties without affecting the business concept being expressed. In this case, we are making a true modification—a new version of the Domain Event. However, if the changes are significant enough to alter the semantic meaning, we must treat it as a new Domain Event, most likely with a different name that reflects the updated business intent.
That said, it’s important to note that a Domain Event should never be modified directly. There are both semantic and technical reasons for this. Semantically, a Domain Event represents a business concept, and we want that concept to remain consistent in our EventStore and Domain Model. Technically, since a Domain Event is serialized and later deserialized, changing its structure after it has been persisted could prevent events from being correctly retrieved from the EventStore. This could lead to issues reconstructing the aggregate’s state during deserialization.
How can we manage this? By versioning our events. Over time, we may have several versions of a Domain Event (V1, V2, … Vn). However, the business meaning must remain unchanged; if it doesn’t, the event should be renamed. When multiple versions exist, our code must include either individual handlers for each version, or a single handler capable of processing all versions, assigning default values to missing properties as needed.
Event versioning is a complex topic. For further insights, refer to the book “Versioning in an Event Sourced System” by Greg Young.
Conclusions
From a pragmatic standpoint, when sharing information across different Bounded Contexts—especially those belonging to distinct microservices—the temptation to reuse an existing object like a Domain Event is strong. You might think it’s enough to simply add a new Event Handler to the same topic and be done with it.
However, this approach leads to more than just a semantic error. It involves sharing information expressed in the language of one Bounded Context with another that may not understand that same language. In doing so, we violate the principle of the Ubiquitous Language. Additionally, since a Domain Event is part of the Domain Model, it may contain sensitive information that should not be exposed outside of its Bounded Context.
This is not merely a semantic issue—it’s an architectural concern. When two parts of a system share an object, such as a Domain Event, they become coupled. If one function changes, the other must adapt, undermining the independence of the involved microservices. Imagine releasing a new version of a microservice after changing a Domain Event to support a new feature, without notifying subscribers. The communication and coordination overhead would quickly become significant.
Even if, at first, the data being shared is the same as that in the Domain Event, the recommendation is to create a dedicated Integration Event. With minimal effort, you gain the freedom to evolve your Domain Model independently, without having to coordinate every change with other systems. And as we know, freedom is priceless.
In the next article, I’ll explain the importance of adopting Event-Driven architectures.