
DDD, Microservices and… Evolutionary Architectures
Last time, I clarified the concept of modules and modular architecture.
This fourth chapter will focus on evolutionary architecture.
What Is an Evolutionary Architecture?
The architecture of a software application is often compared to that of a building. The idea is that nothing stable can be built without solid foundations. You have to decide from the start whether you’re building a single-story house, an apartment block, or a warehouse. You can’t begin with a small home and end up with a five-story building.
This same mindset often surfaces at the start of every project. The application must handle thousands of simultaneous connections, but without incurring high costs during periods of low activity. In essence, it needs to behave like a small house that can grow into a skyscraper when needed—and then shrink back. Is that possible?
The answer is yes. Otherwise, we wouldn’t be talking about evolutionary architecture: an architecture designed to support change in a guided, incremental, and multi-dimensional way.
That may sound vague. So let’s break down these characteristics to better understand the possible solutions.
To ensure a guided evolution, it’s crucial to have solid automated test coverage. Tests ensure the system continues to work correctly after each change. There’s no doubt that writing tests is simpler in a monolith than in a distributed system based on microservices.
However, if your goal is to achieve scalability and flexibility, microservices seem like the natural choice. But they come with a non-negligible initial complexity. As Fred Brooks noted in his famous essay “No Silver Bullet – Essence and Accident in Software Engineering“, there’s a real risk of introducing significant accidental complexity from the very beginning.
In this context, Warren Buffet’s well-known quote rings especially true:
Risk comes from not knowing what you are doing
If you think investing in good architecture is expensive, try building a system with the wrong one.
But let’s take it step by step.
Guided Change
As mentioned earlier, ensuring that our solution can evolve over time and adapt to new requirements or specifications requires a solid suite of tests. Only then can we be confident that every change won’t introduce regressions or errors.
But which tests help us ensure that changes—especially architectural ones—don’t compromise system stability? We certainly can’t rely solely on unit tests, which are designed for business logic. They’re effective tools, but limited to a specific functional scope.
So, should we consider Behavior-Driven Development (BDD)? That’s not the answer either. BDD tests validate the system’s external behavior, ensuring that features meet expectations. However, they offer no coverage from an architectural standpoint.
There is, however, a category of tests that originated in system operations and is mainly used by DevOps teams. This approach includes performance monitoring, centralized log analysis, and setting alerts for potential anomalies. These are known as fitness functions: tools designed to ensure that architectural requirements continue to be met over time, even as operating conditions change.
Fitness Function
From a developer’s perspective, a fitness function measures how closely a solution aligns with the specifications defined by the solution architect. In other words, it evaluates how well the system “fits” the expected architectural requirements.
But why introduce a test for this? Isn’t it the solution architect’s job to monitor these aspects and step in when needed? No. If the goal is to ensure maximum evolutionary flexibility, then every phase before production release must be as automated as possible.
No developer should work under constant supervision. The team should operate independently, confident that the tests in the build and deployment pipelines will validate compliance with architectural standards. It’s the tests—not manual checks—that should detect architectural violations.
In software architecture, what truly matters is the why behind a decision, not the how of its implementation. The architect should explain the rationale behind each design choice. The implementation itself is the development team’s responsibility—as long as it takes place within a framework protected by appropriate testing.
Practically speaking, there are specific tools for writing this type of test. For those using the .NET framework, Ben Norris developed NetArchTest, a fluent API library that allows you to validate architectural rules. A concrete example is available on GitHub.
This library is inspired by ArchUnit, designed for Java developers who want to apply the same principles.
An Example
Below is a simple but effective architectural test. The goal is to ensure that the Sales.Facade project—the entry point of the Sales module—has no direct dependencies on other system modules.
Why is such a test important? Because we want to ensure that, if the Sales module needs to evolve into a standalone microservice in the future, the extraction process will be seamless. The absence of direct dependencies on the rest of the solution is a critical condition to guarantee that level of portability.
[Fact]
public void Should_SalesArchitecture_BeCompliant()
{
var types = Types.InAssembly(typeof(ISalesFacade).Assembly);
var forbiddenAssemblies = new List
{
"BrewUp.Sagas",
"BrewUp.Purchases.Facade",
"BrewUp.Purchases.Domain",
"BrewUp.Purchases.Messages",
"BrewUp.Purchases.ReadModel",
"BrewUp.Purchases.SharedKernel",
"BrewUp.Warehouses.Facade",
"BrewUp.Warehouses.Domain",
"BrewUp.Warehouses.Messages",
"BrewUp.Warehouses.Infrastructures",
"BrewUp.Warehouses.ReadModel",
"BrewUp.Warehouses.SharedKernel",
"BrewUp.Production.Facade",
"BrewUp.Production.Domain",
"BrewUp.Production.Messages",
"BrewUp.Production.Infrastructures",
"BrewUp.Production.ReadModel",
"BrewUp.Production.SharedKernel",
"BrewUp.Purchases.Facade",
"BrewUp.Purchases.Domain",
"BrewUp.Purchases.Messages",
"BrewUp.Purchases.Infrastructures",
"BrewUp.Purchases.ReadModel",
"BrewUp.Purchases.SharedKernel"
};
var result = types
.ShouldNot()
.HaveDependencyOnAny(forbiddenAssemblies.ToArray())
.GetResult()
.IsSuccessful;
Assert.True(result);
}
Incremental
Now that we’ve addressed the topic of guided growth, we can shift our focus to incremental growth. In truth, there’s little to add beyond what is already well established in the context of modular architectures.
It’s important to clarify that modular architectures—a topic that’s been receiving a lot of attention recently—are far from a new concept. Back in 1971, David Lorge Parnas outlined their benefits in his paper “On the Criteria to Be Used in Decomposing Systems into Modules“. He categorized the advantages into three main areas: managerial, product flexibility, and system comprehensibility.
- Managerial: Dividing the system into modules allows different teams to work in parallel. This reduces overall development time and minimizes the need for constant communication among groups.
- Product flexibility: Modifying a single, independent module is simpler and less invasive than changing an entire system. In this context, it’s worth clarifying what we really mean by a legacy system: not just software built with outdated technologies, but a solution still in use and in production whose evolution is difficult due to high component coupling and lack of automated tests.
- System comprehensibility: Analyzing one module at a time makes the system easier to understand and manage, which leads to more effective solutions.
All these principles were formalized well before the introduction of Domain-Driven Design and the “modern” approaches commonly used today.
Cohesion vs. Coupling
In a modular architecture, each module must maintain maximum independence from the others. This means avoiding any form of static coupling between modules. When interaction is necessary, communication should occur through the exchange of messages.
Within a single module, however, objects can be interdependent. Here, we talk about cohesion rather than coupling. Internal components share a common goal, contributing to the solution of a specific part of the overall system.
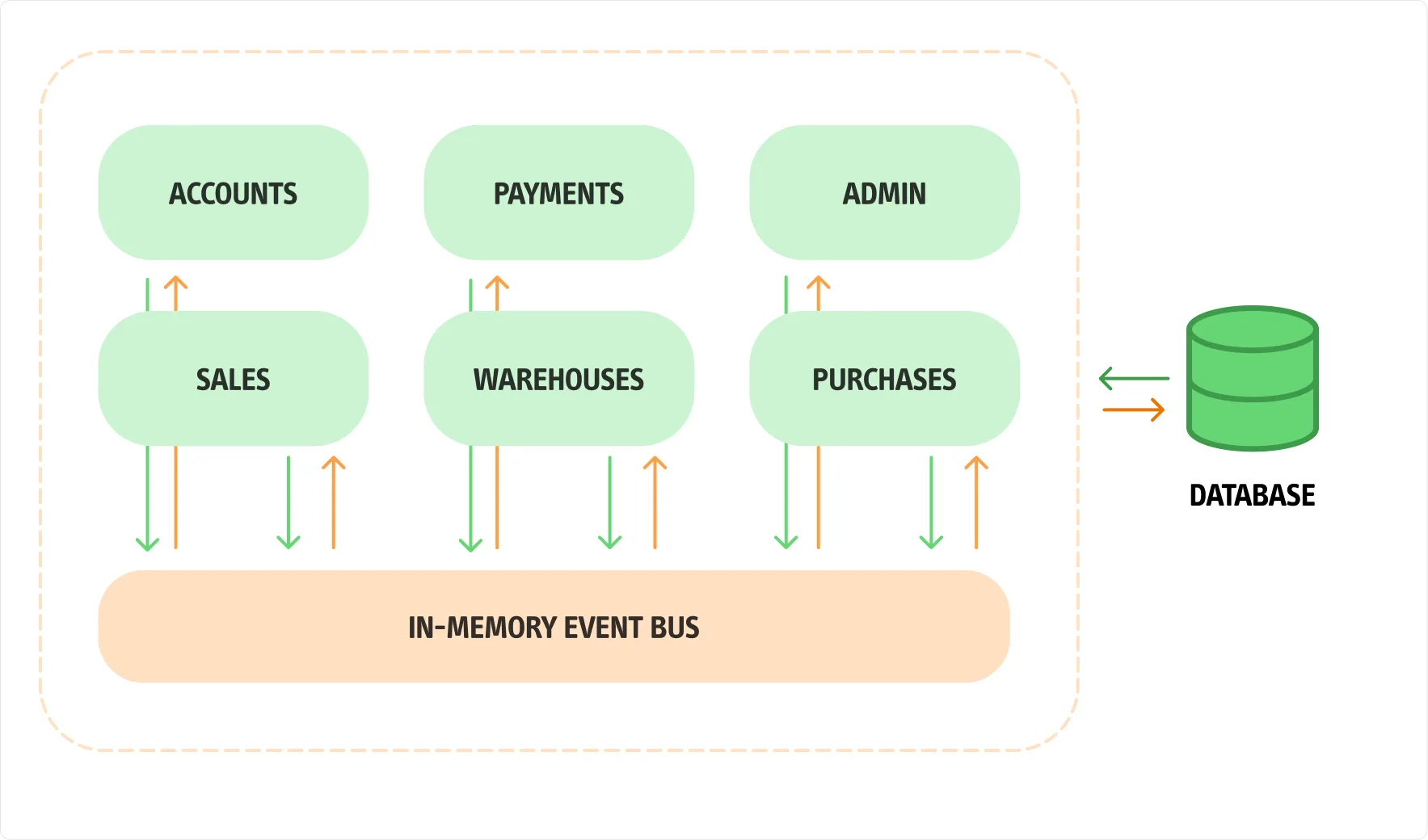
Characteristics of Modular Architecture
Analyzing the image, we can highlight some advantages that a modular architecture offers compared to a microservices solution. First, the Service Bus used for communication between modules can be implemented in-memory. This removes the need for an external Broker for message exchange, while preparing the system to support this pattern to ensure proper isolation between modules.
There is also no need to configure multiple database instances: a single database engine can be used, with one schema per module. This reduces accidental complexity and focuses instead on pragmatic solutions to manage essential complexity.
I do not mean to say that moving from a modular architecture to a microservices-based one requires no effort. What I claim is that it will be possible, because each module is logically separated from the others, both in terms of communication and data persistence.
Of course, we will need to introduce a Broker to handle messages, as the in-memory solution will no longer be feasible. However, in the initial phase, we can deliver a working solution to the client more quickly.
It’s important to remember that testing a monolithic system is definitely easier than testing a distributed one. Also, if we need to modify modules by moving objects between them due to new domain insights, we can do so more smoothly in a monolithic system than in a distributed architecture.
A practical example of a modular solution implemented in C# is available on GitHub.
Multiple Dimension
Let’s now examine the final property of an evolutionary architecture: growth in multiple directions. Why do experienced developers fear distributed systems?
The simple answer is that if you search for guidance on implementing a software architecture tailored to your needs, you won’t find a single definitive answer. Instead, you will encounter a range of applicable patterns. The next question is: which patterns should I apply to my specific case? And, more importantly, how should I apply them?
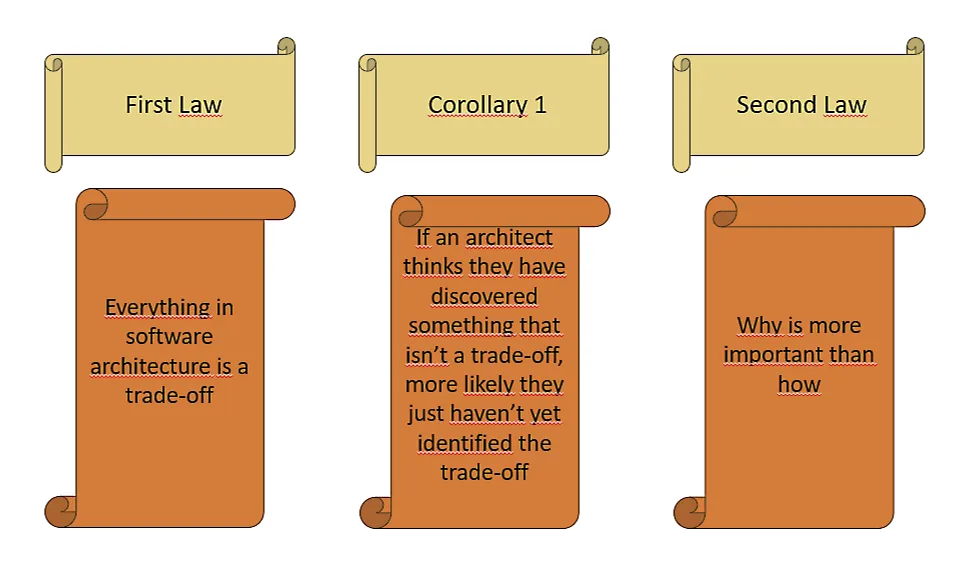
Remember the second law of software architecture? The “Why” is far more important than the “How.” If there is a second law, it means there must be a first one as well, which states: when it comes to software architecture, everything is a trade-off. If someone believes they have found a compromise-free solution, it simply means they haven’t yet found the right trade-off.
Scaling: How and in Which Direction?
Ensuring growth in multiple dimensions means not only addressing a scalable and maintainable codebase but also relying on tests at all levels: from unit tests to end-to-end tests.
A truly distributed system must be able to scale when circumstances demand it. By “scale,” we mean the ability to expand elastically—not just to grow under stress but also to shrink when the load decreases. Additionally, in a distributed system, it is essential to constantly monitor all services to ensure they remain healthy and do not compromise the system’s overall operation.
But here comes a new challenge. What would happen if the deployment of one microservice compromised the entire system? This is not about a distributed monolith, which would be the worst case. Suppose each microservice is autonomous, implements part of the business logic, has its own database for data persistence, and communicates exclusively through messages. If one of these microservices fails, would users still be able to use the application? Or would the entire system be compromised?
The Impact of Changes
Reflecting on Fred Brooks’ article “No Silver Bullet. Essence and Accident in Software Engineering“, we realize that accidental complexity is not destined to decrease. It may change form, but it will certainly continue to occupy a significant part of our system.
To ensure that the business area our Team is working on is truly autonomous, we must also guarantee that its application-level impact is isolated. So, if we think about it, the Bounded Context alone is no longer enough: the concept of isolation must be expanded. As the authors of “Software Architecture: The Hard Parts” state:
Bounded Context is not Enough!
In distributed applications, ensuring that the deployment of one microservice does not hinder the rest of the system is critical. Consider the Netflix app: sometimes the row of series we were watching or recommended movies based on our experience may not load immediately, but the app never stops working. Some services might load late, but they will never block the entire application.
This outcome is the result of years of using fitness functions, such as Chaos Engineering, during the development cycle. This approach allows the system to grow not only in terms of functionality but also in multidimensional scalability. In this context, the Bounded Context alone cannot guarantee a microservice’s independence, as there are aspects beyond Domain-Driven Design patterns that we cannot ignore when managing distributed systems.
Architecture Quantum
I first came across the term architecture quantum while reading the book “Building Evolutionary Architecture“. The term “Quantum” refers to a distributable “artifact” that is independently deployable, with high functional cohesion, strong static coupling, and synchronous dynamic coupling. In simple terms, it is a well-structured microservice that encompasses everything from persistence to UI within a workflow.
The core idea behind an architecture quantum is to be able to deploy a completely independent artifact so that, in case of malfunction, it does not compromise the operation of the entire system. We might lose access to some functionalities, but we will never be completely blocked.
An architecture quantum measures various aspects of the software architecture’s topology and behavior, precisely as required by an evolutionary architecture, taking into account how the involved parts connect and communicate with each other.
Static Coupling
Static coupling represents how static dependencies are resolved within the architecture through contracts. These dependencies include the operating system, frameworks and/or libraries used for system development, and any other operational requirements necessary for the quantum to function.
Dynamic Coupling
Dynamic coupling concerns how the quanta communicate at runtime, both synchronously and asynchronously. For this type of coupling, fitness functions are applied to monitor system performance and health status.
Fundamental Principles
What are the key principles to support the development of evolutionary architectures? The answer is yes, and below we summarize the most important ones.
Last Responsible Moment
Although procrastination may seem counterproductive in some cases, in architecture it is not only recommended but beneficial.
It is crucial to delay critical architectural decisions until you have gathered as much information as possible. This minimizes ignorance about the domain you are addressing.
Architect and Develop for Evolvability
This principle highlights the importance of designing with future evolution in mind.
Before making changes, you must fully understand the system. Let’s recall the concept of “Problem Space vs Solution Space”: do not rush to leave the Problem Space without proper exploration.
Postel’s Law
Also known as the “robustness principle,” Postel’s Law states: “Be conservative in what you send, be liberal in what you accept.”
This means keeping a strict format for the data you send externally, avoiding changes that force others to adapt. At the same time, you should handle incoming data with maximum flexibility.
Conway’s Law
One of the most famous laws in software engineering says: “Organizations that design systems are constrained to produce designs that mirror their own communication structures.”
Conclusions
Evolutionary architectures cover a very broad topic. Here, we only touched on the main aspects, aiming to understand how to approach refactoring an existing application or starting a new project. The books I mentioned are essential resources, full of patterns and details, and in my opinion, must-reads for anyone wanting to deepen their knowledge.
At this point, a natural question arises: can a monolith be considered an architecture quantum? In some cases, yes, since it has strong static coupling, which is a key feature, but usually lacks high functional cohesion. Inside a monolith, responsibilities related to business problems are rarely separated; typically, business logic is shared across all subdomains.
A modular monolith can come closer to being a “quantum,” but it is crucial to consider the database dependency: if a single database is used, it is not a “quantum.” However, if each module has its own schema, we could gain more autonomy in design choices, though attention is needed for UI dependencies. Ultimately, a distributed system fits better with an organization structured around “quanta” than a monolith.
In the next article, I will discuss some of the most important tactical patterns — already covered in the well-known book “” by Eric Evans — and the risks related to sharing Domain Events.