
DDD, Microservices, and Evolutionary Architectures: Event Sourcing Is Not Event Streaming
Last time, we wrapped up with the topic of architectural sustainability.
In this ninth and second-to-last chapter of the DDD series, I’ll talk about two well-known concepts that are often confused: Event Sourcing and Event Streaming.
Words Matter
In the software development world, some trending terms can create confusion, especially when they sound similar but represent distinct concepts. One example? Event Sourcing and Event Streaming: both play a key role in modern architectures but serve different needs and apply in separate contexts.
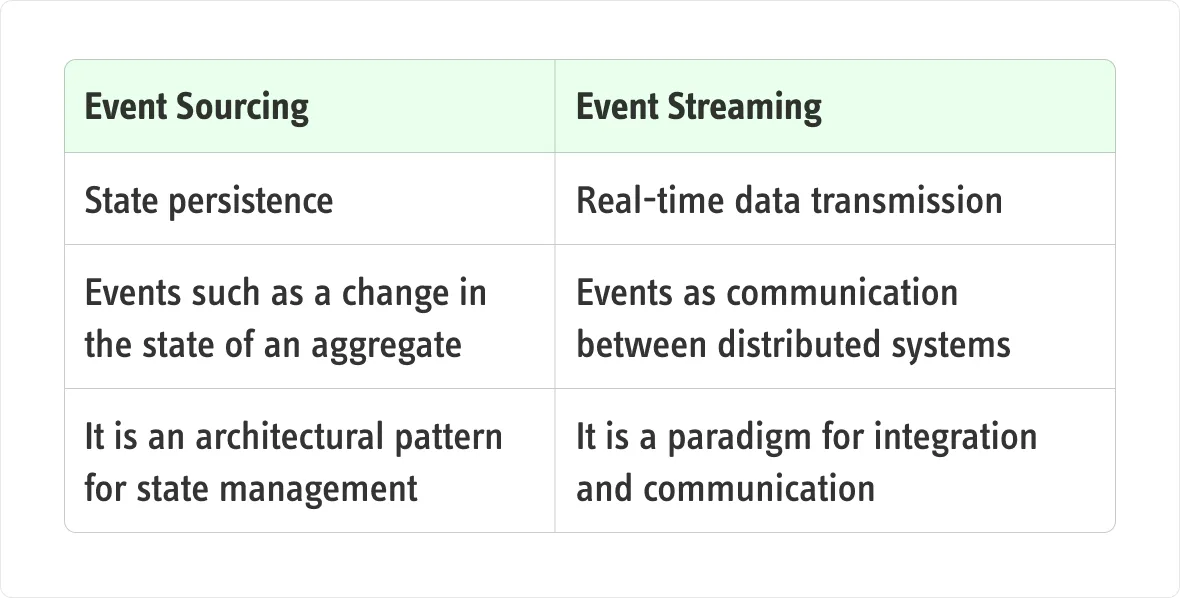
Event Sourcing
Event Sourcing is an architectural pattern where every change in the state of a system—especially of an aggregate, using the terminology from Domain-Driven Design—is represented as an immutable event and stored in chronological order. This approach allows you to rebuild the system’s state at any point by simply replaying the events.
A database designed for this architecture must support optimistic concurrency. In practice, it always allows reading events but enforces constraints only during updates. Since each event represents an unchangeable fact that has already occurred, the only control happens when attempting to append a new event.
Each Event Store assigns a version number, or sequence number, to every event. If two operations try to write simultaneously to the same aggregate’s stream, the system checks the version. Only if the aggregate’s version matches the latest stream version is the event saved and the version updated. Otherwise, the write is rejected.
This mechanism is crucial to ensure Strong Consistency of the aggregate. In an event-driven architecture, Eventual Consistency applies to the read models—as foreseen by the CQRS+ES pattern—while Strong Consistency governs the write model.
In summary, an Event Store must:
- guarantee a complete history of state changes, useful for auditing and retrospective analysis;
- store an immutable sequence of events.
An Event Store database is the ideal partner in a CQRS architecture when you want to save Domain Events—the events that describe system behavior—to reconstruct aggregate state.
A concrete example is an e-commerce system. Here, Event Sourcing can track events such as “CartOrderCreated,” “CreditCardPaymentConfirmed,” or “HighPriorityOrderShipped.” This not only allows reconstructing the full history of an order but also gaining deep insights into the business process. For this reason, the Event Store represents the system’s source of truth.
Event Streaming
The second key player in this comparison is Event Streaming. This paradigm focuses on the real-time movement of information—essentially data—from one point to another within a distributed system. Common tools implementing this include Kafka, RabbitMQ, Azure Service Bus, AWS SQS, and SNS.
Any component in a distributed system can subscribe to these streams to receive data in real time. This data triggers various actions, such as database updates, IoT device activation, or financial transactions on a banking platform.
Event Streaming systems are not designed to replace a database. Although they offer storage capabilities, these are intended to ensure resilience and fault tolerance. They are not built for typical relational database use. Thanks to these features, the system can handle situations like broker service interruptions or temporary unavailability of the receiving system effectively.
It’s true that these systems also maintain an append-only log, much like an Event Store. However, the events they contain cannot be considered a system’s source of truth—at least, not in the same way as an Event Store.
Comparison
Events can only be considered a source of truth when used in the write model to reconstruct the state of an aggregate. When events are used to build a read view, the truth is delegated to an external storage system. This introduces the risk that other streams might update the same storage, compromising the consistency of the facts recorded for that aggregate. Using Event Streaming tools as if they were Event Sourcing systems leads directly to this issue.
Another critical point concerns stream length. In Kafka, for example, the number of events in a Topic doesn’t affect performance—the Topic is a communication channel, not a persistent store. In contrast, in an Event Store, each stream is a part of the database. The more events it contains, the heavier it becomes, with a direct impact on overall performance. Additionally, overly long streams make event versioning more complex—a key aspect of the CQRS+ES model, though beyond the scope of this article.
Conclusions
It’s easy to be tempted by the idea of using an Event Streaming system as a catch-all solution. Its promises may seem appealing, but over time, this approach can lead to more problems than benefits. Software development is not about technical elegance—it’s primarily about solving business problems.
Since business problems constantly evolve, our systems must evolve as well. That’s why it’s essential to use each tool for the purpose it was designed for. Doing so makes it easier to eliminate some of the accidental complexity that often slows development and weakens the overall architecture.
In the final article of this series, I’ll talk about the role of the Software Architect and why it matters.