
DDD, microservizi e architetture evolutive: evolutionary architecture
L’ultima volta ho fatto un po’ di chiarezza sul concetto di modulo e architettura modulare.
Questo quarto capitolo, della serie a tema DDD, che parla di evolutionary architecture, o architetture evolutive, prende spunto da un mio altro scritto già pubblicato nella rivista web MokaByte e consultabile a questo link.
Che cos’è un’architettura evolutiva?
Spesso l’architettura di un’applicazione software viene paragonata a quella di un edificio. L’idea è che, senza solide fondamenta, non sia possibile costruire nulla di stabile. Bisogna decidere fin dall’inizio se si vuole realizzare una casa a un piano, un condominio oppure un capannone. Non si può iniziare con una casetta e concludere con un edificio di cinque piani.
Lo stesso approccio si ripresenta all’avvio di ogni progetto. L’applicazione deve gestire migliaia di connessioni simultanee, ma senza costi eccessivi nei momenti di bassa attività. In sostanza, serve qualcosa che funzioni come una casetta, ma che possa trasformarsi in un grattacielo quando necessario, per poi tornare a essere una casetta. È possibile?
La risposta è sì. Altrimenti, non parleremmo di evolutionary architecture: un’architettura pensata per supportare il cambiamento in modo guidato, incrementale e su più dimensioni.
Detto così può sembrare vago. Proviamo allora ad analizzare queste caratteristiche per capire quali soluzioni possono essere adottate.
Per garantire un’evoluzione guidata è fondamentale introdurre una buona copertura di test automatici. I test assicurano che, a ogni modifica, il sistema continui a funzionare correttamente. Non c’è dubbio che scrivere test in un monolite sia più semplice rispetto a un sistema distribuito basato su microservizi.
Tuttavia, se vogliamo ottenere scalabilità e flessibilità, i microservizi sembrano la scelta naturale. Ma portano con sé una complessità iniziale non trascurabile. Come affermava Fred Brooks nel suo celebre scritto “No Silver Bullet – Essence And Accident in Software Engineering“, si rischia di introdurre fin da subito una significativa complessità accidentale.
In questo contesto, la celebre frase di Warren Buffet risuona con forza:
Risk comes from not knowing what you are doing
Se pensate che investire in una buona architettura sia costoso, provate a costruire un sistema con un’architettura sbagliata.
Ma procediamo con ordine.
Cambiamento guidato
Come accennato, per garantire che la nostra soluzione possa evolvere nel tempo, adattandosi a nuove esigenze o specifiche, è fondamentale predisporre una solida batteria di test. Solo così possiamo essere certi che ogni modifica non introduca regressioni o errori.
Ma quali test ci aiutano a garantire che i cambiamenti, soprattutto a livello architetturale, non compromettano la stabilità del sistema? Di certo non possiamo contare unicamente sugli unit test, pensati per la logica di business. Sono strumenti efficaci, ma limitati a un ambito funzionale specifico.
Potremmo allora considerare il Behavior-Driven Development (BDD)? Neanche questa è la soluzione. I test BDD validano il comportamento esterno del sistema, assicurando che le funzionalità rispondano correttamente alle attese. Tuttavia, non offrono copertura sul piano architetturale.
Esiste però una categoria di test nata in ambito sistemistico e utilizzata soprattutto dagli operatori DevOps. Questo approccio include il monitoraggio delle prestazioni, l’analisi dei log centralizzati e l’impostazione di alert su eventuali anomalie. Parliamo delle fitness function: strumenti pensati per garantire che i requisiti architetturali continuino a essere rispettati nel tempo, anche al variare delle condizioni operative.
Fitness Function
Dal punto di vista dello sviluppatore, una fitness function misura quanto una soluzione sia aderente alle specifiche previste dal solution architect. In altre parole, valuta quanto il sistema “fitta” i requisiti architetturali attesi.
Ma perché è necessario introdurre un test per farlo? Non dovrebbe essere compito del solution architect monitorare questi aspetti e intervenire in caso di problemi? No. Se l’obiettivo è garantire la massima flessibilità evolutiva, allora ogni fase che precede il rilascio in produzione deve essere automatizzata quanto più possibile.
Nessuno sviluppatore dovrebbe lavorare sotto controllo costante. Il team deve potersi muovere con autonomia, certo che i test presenti nelle pipeline di build e deploy verificheranno la conformità alle specifiche. Saranno questi test, e non l’intervento umano, a segnalare eventuali violazioni architetturali.
In architettura, ciò che conta davvero è il perché di una decisione, non il come viene implementata. L’architetto deve motivare le scelte progettuali. L’implementazione, invece, spetta al team di sviluppo, purché avvenga in un contesto protetto da test adeguati.
Passando alla pratica, esistono strumenti specifici per scrivere questo tipo di test. Per chi utilizza il framework .NET, Ben Norris ha sviluppato NetArchTest, una libreria basata su fluent API che consente di verificare le regole architetturali. Un esempio concreto di applicazione è disponibile su GitHub.
Questa libreria prende ispirazione da ArchUnit, pensata per chi sviluppa in Java e desidera applicare gli stessi principi.
Un esempio
Di seguito è riportato un esempio semplice, ma efficace, di test architetturale. L’obiettivo è garantire che il progetto Sales.Facade, punto di ingresso del modulo Sales, non presenti dipendenze dirette verso altri moduli del sistema.
Perché è importante introdurre un test del genere? Perché vogliamo assicurarci che, qualora in futuro il modulo Sales debba evolversi in un microservizio indipendente, l’operazione di estrazione avvenga senza ostacoli. L’assenza di dipendenze dirette con il resto della soluzione è una condizione fondamentale per garantire questa portabilità.
[Fact]
public void Should_SalesArchitecture_BeCompliant()
{
var types = Types.InAssembly(typeof(ISalesFacade).Assembly);
var forbiddenAssemblies = new List
{
"BrewUp.Sagas",
"BrewUp.Purchases.Facade",
"BrewUp.Purchases.Domain",
"BrewUp.Purchases.Messages",
"BrewUp.Purchases.ReadModel",
"BrewUp.Purchases.SharedKernel",
"BrewUp.Warehouses.Facade",
"BrewUp.Warehouses.Domain",
"BrewUp.Warehouses.Messages",
"BrewUp.Warehouses.Infrastructures",
"BrewUp.Warehouses.ReadModel",
"BrewUp.Warehouses.SharedKernel",
"BrewUp.Production.Facade",
"BrewUp.Production.Domain",
"BrewUp.Production.Messages",
"BrewUp.Production.Infrastructures",
"BrewUp.Production.ReadModel",
"BrewUp.Production.SharedKernel",
"BrewUp.Purchases.Facade",
"BrewUp.Purchases.Domain",
"BrewUp.Purchases.Messages",
"BrewUp.Purchases.Infrastructures",
"BrewUp.Purchases.ReadModel",
"BrewUp.Purchases.SharedKernel"
};
var result = types
.ShouldNot()
.HaveDependencyOnAny(forbiddenAssemblies.ToArray())
.GetResult()
.IsSuccessful;
Assert.True(result);
}
Incremental
Affrontata la questione della crescita guidata, possiamo ora concentrarci sulla crescita incrementale. In realtà, su questo tema c’è poco da aggiungere rispetto a quanto già consolidato nel contesto delle architetture modulari.
È importante chiarire fin da subito che le architetture modulari, di cui oggi si parla con insistenza, non sono affatto un concetto recente. Già nel 1971, David Lorge Parnas nel suo scritto “On the criteria to be used in decomposing systems into modules” ne descriveva in modo dettagliato i vantaggi, suddividendoli in tre ambiti principali: manageriale, flessibilità del prodotto e comprensibilità del sistema.
- Manageriale: la suddivisione in moduli consente a team diversi di lavorare in parallelo, riducendo i tempi di sviluppo complessivi e la necessità di comunicazione continua tra i gruppi.
- Flessibilità del prodotto: modificare un singolo modulo, progettato per essere indipendente, è più semplice e meno invasivo rispetto a intervenire sull’intero sistema. In questo contesto è utile ricordare cosa si intende realmente per sistema legacy: non un’applicazione basata su tecnologie obsolete, ma una soluzione ancora in uso e produttiva, la cui evoluzione è complessa a causa dell’elevato accoppiamento tra i componenti e della mancanza di test automatizzati.
- Comprensibilità del sistema: affrontare l’analisi di un modulo alla volta rende il sistema più leggibile e gestibile, favorendo lo sviluppo di soluzioni più efficaci.
Tutti questi principi sono stati formalizzati ben prima dell’introduzione del Domain-Driven Design e degli approcci “moderni” oggi più diffusi.
Coesione vs. accoppiamento
In un’architettura modulare, ogni modulo deve mantenere la massima indipendenza dagli altri. Ciò significa evitare qualsiasi forma di accoppiamento statico tra i moduli. Quando è necessario farli interagire, la comunicazione deve avvenire attraverso lo scambio di messaggi.
All’interno di un singolo modulo, invece, può esserci interdipendenza tra gli oggetti: in questo contesto si parla di coesione piuttosto che di accoppiamento. I componenti interni condividono infatti uno stesso obiettivo, contribuendo alla soluzione di una specifica parte del sistema complessivo.
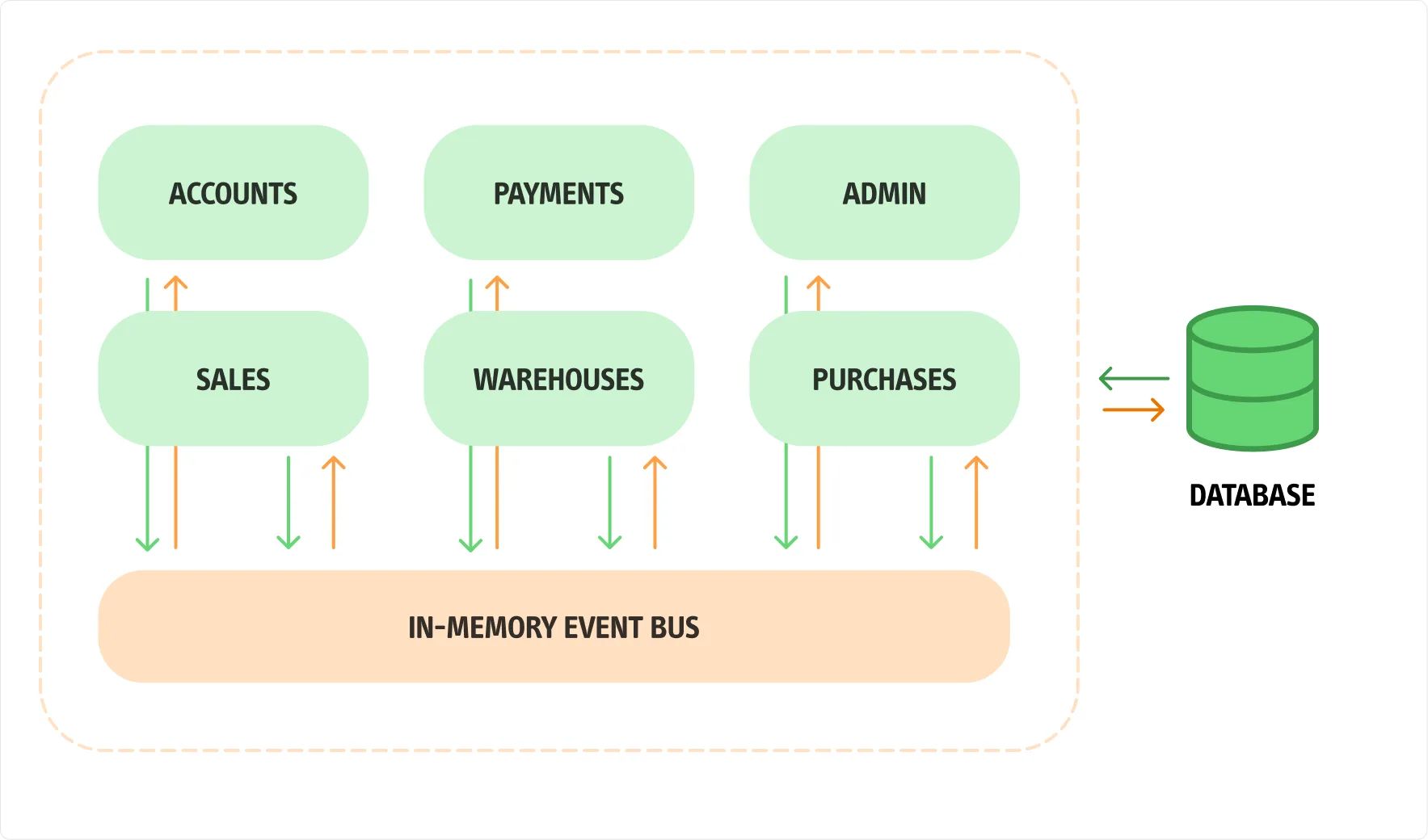
Le caratteristiche dell’architettura modulare
Analizzando l’immagine, possiamo evidenziare alcuni vantaggi che un’architettura modulare offre rispetto a una soluzione a microservizi. In primo luogo, il Service Bus utilizzato per la comunicazione tra i moduli può essere implementato in memoria. Questo elimina la necessità di un Broker esterno per lo scambio delle informazioni, ma allo stesso tempo prepara il sistema a supportare questo pattern per garantire il giusto isolamento tra i moduli. Non è nemmeno necessario configurare diverse istanze di database: si può utilizzare un unico motore di database, con uno schema per ogni modulo. In questo modo, si riduce la complessità accidentale, concentrandosi invece sulla soluzione pragmatica per gestire la complessità essenziale.
Non intendo dire che passare da un’architettura modulare a una basata su microservizi non richieda lavoro. Ciò che sostengo è che sarà innanzitutto possibile, perché ogni modulo è logicamente separato dagli altri, sia per quanto riguarda la comunicazione che la persistenza dei dati. Naturalmente, dovremo introdurre un Broker per gestire i messaggi, dato che la soluzione in memoria non sarà più praticabile. Tuttavia, nella fase iniziale, saremo in grado di fornire al cliente una soluzione funzionante in tempi più rapidi.
È importante ricordare che testare un sistema monolitico è decisamente più semplice rispetto a testare un sistema distribuito. Inoltre, nel caso in cui sia necessario modificare i moduli, spostando oggetti tra di essi a seguito di una nuova scoperta sul dominio complessivo, potremo farlo con maggiore serenità in un sistema monolitico rispetto a un’architettura distribuita.
Un esempio pratico di implementazione di una soluzione modulare in C# è disponibile su GitHub.
Multiple Dimension
Analizziamo ora l’ultima delle proprietà di un’architettura evolutiva: la crescita in più direzioni. Perché ogni sviluppatore esperto teme i sistemi distribuiti?
La risposta semplice è che, se cercate informazioni su come implementare un’architettura software adatta alle vostre esigenze, non troverete risposte univoche. Piuttosto, incontrerete una serie di pattern applicabili. La domanda successiva è: quali pattern devo applicare al mio caso specifico? E soprattutto, come devo applicarli?
Ricordate la seconda legge delle architetture software? Il “Perché” è molto più importante di “come”. Se esiste una seconda legge, significa che deve esserci anche una prima, che recita: quando si parla di architettura software, tutto è un compromesso. Se qualcuno crede di aver trovato una soluzione senza compromessi, significa semplicemente che non ha ancora trovato il giusto compromesso.
Scalare: come e in che direzione?
Garantire la crescita su più dimensioni comporta non solo affrontare il tema di una codebase scalabile e facilmente mantenibile, ma anche fare affidamento sui test a tutti i livelli: dagli unit test fino ai test End-to-End.
Un sistema distribuito degno di questo nome deve essere in grado di scalare quando le circostanze lo richiedono. Con “scalare” intendiamo la capacità di espandersi in modo elastico: non solo in grado di crescere sotto stress, ma anche di ridursi quando il carico diminuisce. Inoltre, in un sistema distribuito, è fondamentale monitorare costantemente tutti i servizi per garantire che siano in salute e non compromettano l’intero funzionamento del sistema.
Ma qui si presenta una nuova sfida. Cosa accadrebbe se il rilascio di un microservizio compromettesse l’intero sistema? Non parliamo del caso di un monolite distribuito, che sarebbe la soluzione peggiore. Supponiamo che ogni microservizio sia autonomo, implementi una parte della logica di business, abbia il proprio database per la persistenza dei dati e comunichi esclusivamente tramite messaggi. Se uno di questi microservizi dovesse fallire, gli utenti continuerebbero ad utilizzare l’applicazione? Oppure l’intero sistema verrebbe compromesso?
Gli impatti delle modifiche
Ripensando all’articolo di Fred Brooks “No Silver Bullet. Essence and Accident in Software Engineering“, possiamo riflettere sul fatto che la complessità accidentale non è destinata a diminuire. Potrà mutare, ma sicuramente continuerà a occupare una parte significativa del nostro sistema.
Per garantire che la parte di business su cui stiamo lavorando come Team sia effettivamente autonoma, dobbiamo assicurarci che anche l’impatto a livello applicativo lo sia. Ma allora, se ci pensiamo bene, il solo Bounded Context non è più sufficiente: è necessario espandere il concetto di isolamento. Come affermano gli autori di “Software Architecture: The Hard Parts“:
Bounded Context is not Enough!
Nel contesto delle applicazioni distribuite, la garanzia che il rilascio di un microservizio non ostacoli il resto del sistema è cruciale. Pensiamo, ad esempio, all’applicazione di Netflix: può capitare che non venga visualizzata subito la riga delle serie che stavamo guardando o dei film consigliati in base alla nostra esperienza, ma non che l’applicazione smetta di funzionare. Alcuni servizi potrebbero caricarsi in ritardo, ma non bloccheranno mai l’intera applicazione.
Questo risultato è il frutto di anni di utilizzo di fitness functions come il Chaos Engineering nel ciclo di sviluppo. In questo modo, è possibile garantire la crescita del sistema non solo in termini di funzionalità, ma anche di scalabilità multidimensionale. In questo contesto, il Bounded Context da solo non è sufficiente a garantire l’indipendenza di un microservizio, poiché ci sono aspetti che vanno oltre i pattern del Domain-Driven Design, ma che non possiamo ignorare quando gestiamo sistemi distribuiti.
Architecture quantum
Di architecture quantum ho sentito parlare per la prima volta leggendo il libro “Building Evolutionary Architecture“. Il termine “Quantum” si riferisce a un “manufatto” distribuibile in modo indipendente, con una coesione funzionale elevata, un forte accoppiamento statico e un accoppiamento dinamico sincrono. In poche parole, un microservizio ben strutturato, che va dalla persistenza alla UI, all’interno di un flusso di lavoro.
L’idea alla base di un architecture quantum è proprio quella di poter distribuire un artifact completamente indipendente dagli altri, in modo tale che, nel caso di malfunzionamento, non comprometta il funzionamento dell’intero sistema. Potremmo non avere accesso ad alcune funzionalità, ma non saremo mai completamente bloccati.
Un architecture quantum misura diversi aspetti della topologia e del comportamento dell’architettura software, proprio come richiesto da un’architettura evolutiva, considerando il modo in cui le parti in gioco si collegano e comunicano tra loro.
Static Coupling
Lo static coupling rappresenta il modo in cui le dipendenze statiche si risolvono all’interno dell’architettura tramite contratti. Queste dipendenze comprendono il sistema operativo, i framework e/o le librerie utilizzate per lo sviluppo del sistema, e qualsiasi altro requisito operativo necessario al funzionamento del quantum.
Dynamic Coupling
Il dynamic coupling riguarda il modo in cui i quanta comunicano a runtime, sia in modalità sincrona che asincrona. Per questo tipo di accoppiamento, vengono applicate le fitness function per il monitoraggio delle prestazioni e dello stato di salute del sistema.
Princìpi
Esistono dei principi fondamentali che devono essere rispettati per supportare lo sviluppo delle evolutionary architectures? La risposta è sì, e di seguito cercheremo di riassumerli in modo chiaro.
Last Responsible Moment
Seppur procrastinare possa risultare difficile in alcune situazioni, in questo caso non solo è consigliato, ma è anche benefico. È importante rimandare le decisioni cruciali sull’architettura (e in generale su qualsiasi aspetto critico del sistema) al momento in cui siamo in grado di raccogliere la maggior parte delle informazioni possibili. Dobbiamo ridurre al minimo l’ignoranza nei confronti del sottodominio che stiamo affrontando prima di prendere una decisione.
Architect and develop for evolvability
Se il principio riguarda il progettare prima e sviluppare poi, con un occhio attento alla possibilità di evoluzione del sistema, è fondamentale comprenderlo appieno prima di agire. Non possiamo modificare un sistema che non comprendiamo. Torniamo al concetto di “Problem Space vs Solution Space”: non dobbiamo avere fretta di abbandonare il Problem Space!
Postel’s Law
Il “principio di robustezza” o legge di Postel afferma: “Sii conservatore in ciò che invii, sii liberale in ciò che accetti”. In altre parole, dobbiamo essere molto cauti nel modificare il formato delle strutture dati che inviamo all’esterno, per evitare di obbligare gli altri a seguire le nostre evoluzioni. Al contrario, dovremmo essere più flessibili con i dati che riceviamo.
Conway’s Law
Una delle leggi più note, afferma che: “Le organizzazioni che progettano sistemi sono costrette a produrre progetti che sono copie delle strutture di comunicazione delle organizzazioni stesse.”
Conclusioni
Le evolutionary architecture rappresentano un tema estremamente ampio, di cui abbiamo solo accennato gli aspetti principali, con l’obiettivo di comprendere come affrontare il refactoring di un’applicazione esistente o l’avvio di un nuovo progetto. I libri che ho citato costituiscono una risorsa fondamentale, ricca di pattern e dettagli, e sono, a mio avviso, letture imprescindibili per chiunque desideri approfondire l’argomento.
Una domanda a questo punto sorge spontanea: può un monolite essere considerato un architecture quantum? In alcuni casi sì, in quanto presenta un forte accoppiamento statico, caratteristica fondamentale, ma meno una coesione funzionale elevata. Infatti, all’interno di un monolite, difficilmente si riscontra una separazione delle responsabilità rispetto ai problemi di business; in genere, la logica di business è condivisa tra tutti i sottodomini.
Un monolite modulare può avvicinarsi di più a un “quantum”, ma è fondamentale considerare la dipendenza dal database: se si utilizza un unico database, non siamo di fronte a un “quantum”. Tuttavia, se ogni modulo ha il proprio schema, potremmo avere maggiore autonomia nelle scelte progettuali, sebbene sia necessario prestare attenzione alle dipendenze verso la UI. In definitiva, un sistema distribuito si adatta meglio a un’organizzazione a “quanta” rispetto a un monolite.
Nel prossimo articolo vi parlerò di alcuni dei più importanti pattern tattici – ià trattati nel celebre libro “” di Eric Evans – e dei rischi legati alla condivisione dei Domain Event.