
DDD, microservizi e architetture evolutive: perché non condividere i Domain Event
Nei precedenti articoli di questa collana sul mondo del Domain-Driven Design abbiamo visto i vantaggi legati alla suddivisione di una architettura in moduli – non necessariamente microservizi -, le architetture evolutive e l’importanza dei pattern strategici quali Bounded Context e Ubiquitous Language.
In questo articolo, che prende spunto da un altro mio scritto già pubblicato nella rivista web MokaByte, vi spiegherò di un’altra classe di importanti pattern trattati da Eric Evans nel suo celebre libro ““: i pattern tattici, e di alcune accortezze legate all’utilizzo dei Domain Event.
Progettare per l’evoluzione
Il primo passo per realizzare un’architettura evolutiva è progettare il software in modo che possa adattarsi facilmente al cambiamento. Sembra semplice, ma nella pratica è tutt’altro che immediato.
Cosa significa costruire un sistema capace di evolvere con continuità, seguendo le richieste del Cliente? Partiamo da un caso ricorrente: il codice legacy. Spesso questo termine viene associato a un’applicazione obsoleta, da riscrivere usando tecnologie moderne. Ma questa visione è limitata. Un codice può essere legacy anche se scritto la settimana scorsa.
Ciò che rende un codice legacy è la difficoltà nel modificarlo. L’applicativo genera valore per l’azienda, ma ogni intervento di manutenzione o evoluzione è rischioso. Le forti dipendenze interne tra gli oggetti rendono fragile l’intero sistema: toccare una parte significa potenzialmente dover rivedere tutto il progetto. Ed è comprensibile che questo freni ogni iniziativa di miglioramento.
Il Domain-Driven Design offre un supporto concreto. Per aumentare la manutenibilità di un applicativo, la strategia migliore è suddividerlo in moduli piccoli e coesi. Non è necessario arrivare ai microservizi, ma è fondamentale che ogni modulo sia legato a un’area di business specifica.
In questo senso, i pattern strategici come Ubiquitous Language e Bounded Context risultano preziosi. Tuttavia, non bastano. Un Bounded Context copre comunque un perimetro ampio del dominio aziendale. Il rischio di gestire componenti troppo complessi resta.
Non a caso, E. Evans ha introdotto anche una serie di pattern tattici, pensati per facilitare lo sviluppo concreto dell’applicativo. Non ci soffermeremo su tutti — li trovate nel suo libro — ma analizzeremo quelli più utili a costruire un software duraturo, stabile e facilmente manutenibile.
Aggregate
Tra i pattern tattici del Domain-Driven Design, l’Aggregato è uno dei più rilevanti. Rappresenta una versione semplificata del modello di business che vogliamo implementare. È un pattern centrale e articolato. Un Aggregato è composto da una o più Entity e da uno o più Value Object.
Descritto così può sembrare semplice da progettare. In realtà, definire correttamente un Aggregato è una delle attività più complesse nello sviluppo software. Essendo una rappresentazione semplificata del modello di business, deve rimanere il più fedele possibile alla realtà che descrive.
Senza addentrarci troppo nella teoria, un software riesce a risolvere problemi di business finché il modello implementato non si discosta troppo da quello reale. In pratica, ogni nuova richiesta del cliente dovrebbe essere realizzabile senza dover forzare la struttura del codice.
Ma questo ci riporta al punto di partenza? Assolutamente no. Un Aggregato non è soltanto un contenitore di dati. Deve esporre anche i metodi che ne descrivono il comportamento. Tutta la logica relativa al problema che risolve passa da lui, e solo da lui.
Questo approccio garantisce un importante vantaggio: le modifiche al comportamento del dominio interessano solo l’Aggregato coinvolto, senza propagarsi ad altre parti dell’applicazione. Ogni Aggregato è un’unità autonoma. Comunica con gli altri, certo, ma prende decisioni in modo indipendente, rispettando le regole di business definite al suo interno, ovvero i suoi invarianti.
Le comunicazioni all’interno dell’Aggregate
Per mantenere l’isolamento degli oggetti interni a un aggregato, ogni interazione deve avvenire tramite un’entità specifica: la Aggregate Root (o Entity Root).
Un esempio classico è quello di un ordine di vendita, composto da una “testa” e da più righe. Non è possibile modificare direttamente le righe. Tutte le operazioni devono passare dalla testa dell’ordine, che rappresenta l’Aggregate Root. Sarà questa entità a invocare i metodi appropriati sulle righe e a coordinare eventuali modifiche.
Una volta completata l’operazione, l’Aggregate Root ha anche il compito di validare il rispetto delle regole di business, ovvero degli invarianti. Ad esempio, dovrà verificare che il totale aggiornato dell’ordine non superi il budget disponibile del cliente.
Facilitare la manutenzione e coerenza dei dati
Accentuare i comportamenti in un solo punto del codice è una scelta strategica per la manutenibilità. Limitare il perimetro d’azione dell’aggregato aiuta a contenere la complessità, mantenendo coerenza e chiarezza rispetto al problema che si intende risolvere.
E per quanto riguarda la coerenza dei dati? Il fatto che l’Aggregate Root verifichi il rispetto delle regole di business a ogni variazione di stato garantisce dati coerenti all’interno del sistema. Non è un dettaglio secondario: l’aggregato deve essere consistent fin dalla sua prima istanza.
In ottica tecnica, un aggregato non dovrebbe mai essere creato tramite una factory senza parametri. Una pratica del genere risulta inaccettabile in un dominio ben modellato. Ed è proprio da qui che iniziano le prime sfide legate al dimensionamento corretto degli Aggregati.
Il dimensionamento dell’Aggregate
Un aggregato troppo ampio introduce maggiore complessità e maggiore concorrenza. Sarà più frequente, infatti, che diverse richieste ricadano su di esso. Di conseguenza, dovrà gestire numerosi invarianti e regole di business, rendendo il codice più difficile da mantenere.
Il vantaggio? In termini di consistency, si ottiene un modello più robusto. Un’area d’intervento più ampia garantisce che una quantità maggiore di dati resti coerente a ogni modifica dello stato.
Al contrario, se l’aggregato è più piccolo, si riduce la coerenza dei dati, ma si guadagna in semplicità e gestione della concorrenza.
Un esempio pratico chiarisce il concetto. Immaginiamo un sistema di prenotazione per una multisala. Se consideriamo come aggregato la programmazione dell’intera giornata, otterremo un alto livello di consistenza. Tutte le informazioni — film, sale, orari, posti disponibili — saranno contenute in un unico contesto. Tuttavia, l’aggregato dovrà gestire un’elevata concorrenza.
Se, invece, modelliamo l’aggregato come la sala, il sistema sarà più semplice. L’aggregato dovrà gestire solo le prenotazioni dei posti per una singola proiezione. Potremmo spingerci oltre? Sì: potremmo rendere una fila l’unità di aggregazione.
Qual è la scelta migliore? Dipende dal contesto. Sebbene non esistano aggregati “troppo piccoli” in senso assoluto, è importante evitare suddivisioni eccessive che introducono un carico progettuale inutile. L’equilibrio va sempre trovato in funzione del dominio e dei requisiti reali.
Domain Event
Ora che abbiamo visto come isolare i comportamenti del dominio per rendere le applicazioni più manutenibili, viene spontaneo chiedersi: come possono comunicare tra loro i diversi aggregati?
Se gli aggregati appartengono allo stesso Bounded Context, la soluzione è relativamente semplice. Ogni aggregato ha una propria Aggregate Root incaricata di gestire le interazioni con l’esterno. In questi casi, un Domain Service può orchestrare la comunicazione in modo efficace.
Le cose si complicano quando è necessario notificare un cambiamento di stato a un aggregato situato fuori dal proprio Bounded Context. In questi scenari entra in gioco un pattern fondamentale: il Domain Event.
Ma cosa si intende, esattamente, per Domain Event? Un Domain Event ha due caratteristiche essenziali:
- Descrive un fatto già accaduto. Per questo motivo, il suo nome va espresso sempre al participio passato (es. “OrdineCreato”, “PagamentoRicevuto”).
- È immutabile. Non può essere modificato in alcun modo, proprio perché rappresenta un evento già avvenuto nel passato. Al massimo, può essere compensato da un’azione successiva.
I Domain Event appartengono al modello di dominio. Non sono notifiche generiche: non devono essere distribuiti indiscriminatamente. Un criterio utile per capire se si tratta di un vero evento di dominio è chiedersi: “Questo evento interessa ai domain expert?” Se la risposta è sì, allora è un Domain Event.
A questo punto potremmo chiederci: perché i Domain Event non compaiono nel libro di Evans? La risposta definitiva non è nota. Tuttavia, è chiaro che questo pattern ha assunto maggiore rilevanza con l’evoluzione verso architetture distribuite. In un contesto distribuito, dove i componenti devono essere disaccoppiati, lo scambio di messaggi rappresenta una soluzione naturale.
Il successo dei Domain Event è legato proprio alla diffusione dei microservizi e all’adozione di event-driven architecture. Non a caso, parlando di eventi in ambito Domain-Driven Design, il riferimento immediato è il pattern CQRS+ES (Command Query Responsibility Segregation + Event Sourcing) introdotto da Greg Young.
CQRS
CQRS (Command Query Responsibility Segregation) è l’evoluzione del pattern CQS (Command Query Separation) di Bertrand Meyer, autore del linguaggio Eiffel, e uno dei padri della OOP, che aveva appunto teorizzato la netta separazione fra un’azione che modifica i dati all’interno del database (Command), da una che legge i dati presenti nel database stesso.
La prima è autorizzata a modificare lo stato di un record, ma non necessariamente deve restituire un risultato, se non il fatto che l’operazione è andata, o meno, a buon fine. La seconda, al contrario, non deve assolutamente apportare modifiche al dato, ma deve limitarsi a restituire i dati che corrispondono alla query di interrogazione. Se nessuno apporta modifiche, la query deve sempre restituire lo stesso risultato (idempotente).
L’innovazione di Greg Young a questo pattern è stata la netta separazione del database nelle due fasi, di scrittura e di lettura, del dato. Il punto di partenza è che se un database è ottimizzato per la scrittura, allora non lo sarà per la lettura, e viceversa. Come spesso accade, un’immagine vale più di mille parole.
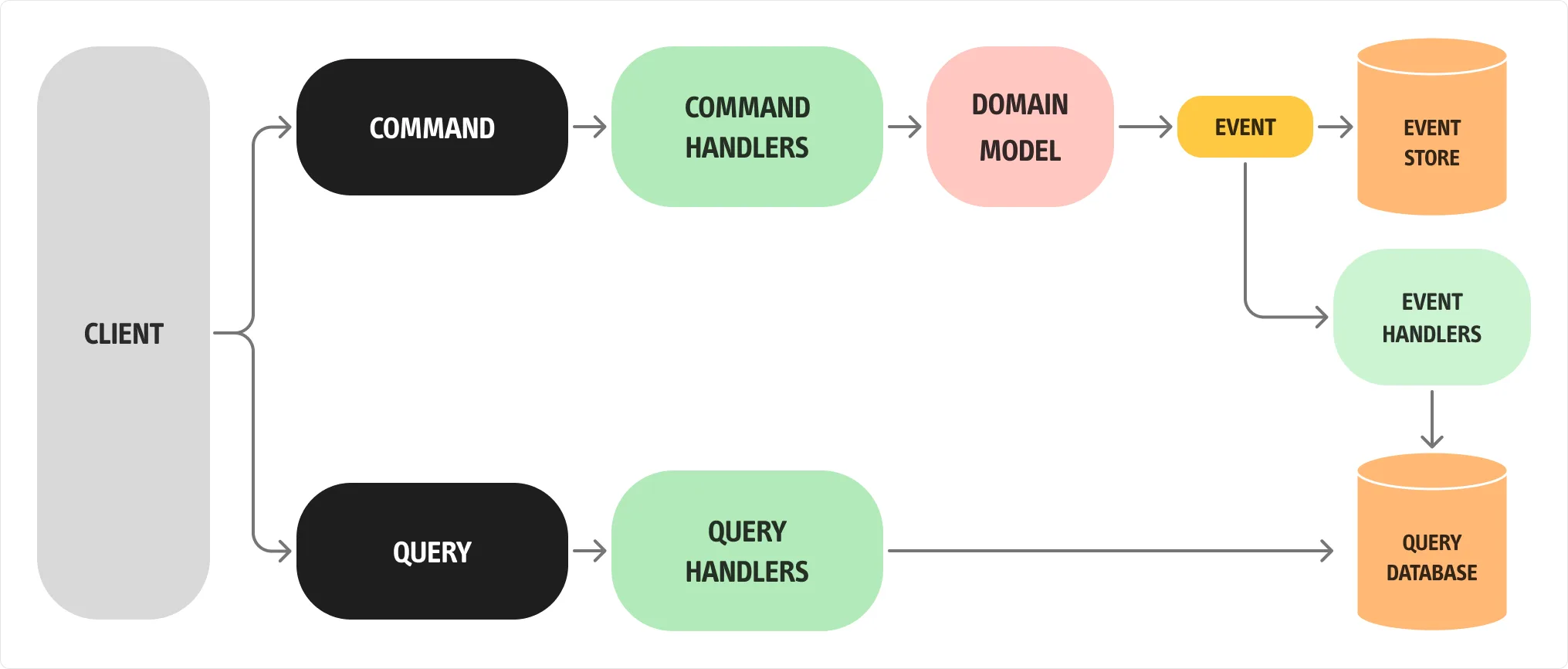
Per comprendere appieno il funzionamento del pattern, analizziamo nel dettaglio i passaggi illustrati nella figura:
- Il Client invia un Command per richiedere una variazione di stato su un Aggregato. Un esempio potrebbe essere: CreaOrdineDiAcquistoDaPortale. È fondamentale che il nome del comando descriva chiaramente l’intento di business che rappresenta.
- Il Command viene preso in carico da un Command Handler. Questo componente si occupa di eseguire i metodi definiti all’interno del Domain Model, ossia dell’Aggregato. Ricordiamo che il Domain Model non deve limitarsi a rappresentare dati, ma deve anche includere la logica di business necessaria a gestire le variazioni di stato.
- L’Aggregato valuta il comando ricevuto. Se l’azione richiesta viola una regola di business (per esempio, il superamento del budget cliente), l’operazione viene respinta. Al termine dell’elaborazione, l’aggregato emette un Domain Event, che rappresenta il fatto appena avvenuto. In un sistema asincrono, è buona pratica emettere eventi anche in caso di fallimento, per permettere alla UI o ad altri componenti di reagire correttamente.
- Il Domain Event viene salvato nell’Event Store. Questo passaggio è essenziale se si utilizza l’Event Sourcing: memorizzare gli eventi è infatti l’unico modo per ricostruire lo stato dell’aggregato a partire dalla sua storia. È possibile utilizzare lo stesso database sia per l’Event Store che per il Read Model, se si vuole mantenere un’architettura semplice.
- L’evento viene quindi pubblicato. Qualsiasi componente o servizio all’interno dello stesso Bounded Context che desideri reagire al cambiamento può sottoscriversi e aggiornare di conseguenza il proprio Read Model.
- Le Query provenienti dal Client non interagiscono con l’Aggregato, ma si appoggiano esclusivamente sul Read Model, che può essere strutturato con diverse projection per supportare le specifiche esigenze della UI.
Domain Event
Il Domain Event è a tutti gli effetti un elemento integrante del modello di dominio: rappresenta un fatto già avvenuto all’interno del dominio applicativo. Invece di salvare semplicemente lo stato corrente di un aggregato, si registrano le singole variazioni di stato sotto forma di eventi di dominio.
Ogni volta che si applica un nuovo comando — o si decide di respingerlo perché viola una regola di business — si ricostruisce l’aggregato rileggendo in sequenza tutti i Domain Event associati. Questo processo consente di ottenere una proiezione aggiornata e consistente dell’oggetto.
È un approccio che sposta la prospettiva: si passa da una “fotografia” dello stato attuale a un vero e proprio “film” che racconta come l’aggregato ha raggiunto la sua configurazione attuale.
Come già anticipato, i Domain Event sono sempre espressi al passato, perché descrivono qualcosa che è già accaduto. Nessun componente del sistema può metterne in discussione la validità: sono fatti consolidati.
Questo approccio offre una significativa flessibilità. La logica di business rimane confinata all’interno dell’Aggregato, evitando la dispersione su più layer o servizi. Ciò rende il sistema più stabile e più semplice da manutenere. Quando si introduce una modifica o si aggiunge un comportamento, è sufficiente garantire che i test continuino a passare: in tal modo si ha la certezza di non compromettere nulla al di fuori del proprio Bounded Context.
Infine, chiunque si sottoscriva a un Domain Event deve trattarlo come un dato immutabile e definitivo. Nessuna logica condizionale deve essere applicata sull’evento ricevuto: si presume che rappresenti una verità storica.
Com’è strutturato un Domain Event?
Un Domain Event è, a tutti gli effetti, un Data Transfer Object (DTO). Contiene le informazioni relative alle modifiche avvenute all’interno dell’aggregato. Nella pratica, questo significa che espone esclusivamente le proprietà che sono cambiate in seguito all’esecuzione di un comando.
Un esempio concreto di implementazione in C# è riportato nella seguente figura.
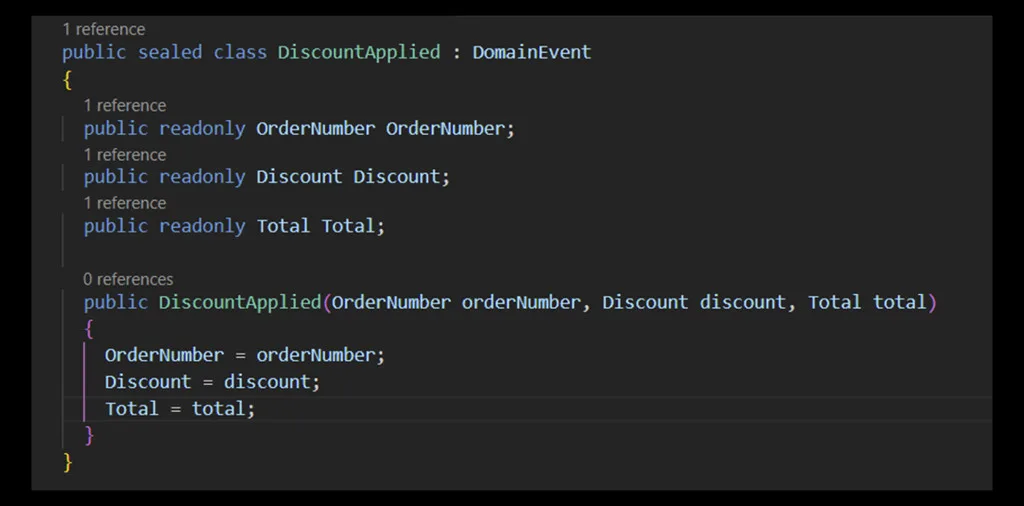
Iniziamo con l’analizzare il codice del Domain Event. La classe è sealed, il che significa che non può essere ereditata, né estesa all’interno del codice. Questa scelta garantisce che il comportamento del Domain Event resti invariato.
Tutte le proprietà della classe sono readonly. Questo approccio ha un motivo preciso: il nostro Domain Event deve essere serializzato prima di essere inviato e successivamente deserializzato al momento della ricezione. Durante queste operazioni, non è permesso alcun intervento che modifichi i dati, per assicurare che il contenuto rimanga integro e senza alterazioni. In altre parole, ciò che esce dal dominio deve arrivare senza modifiche al destinatario.
Un altro aspetto importante da notare riguarda la semantica utilizzata all’interno del Domain Event. Per esprimere le grandezze delle proprietà, non si utilizzano tipi primitivi, ma tipi customizzati, in linea con il linguaggio del business, ossia l’Ubiquitous Language. Se si dovesse utilizzare un tipo primitivo come string o UUID per rappresentare il numero dell’ordine, solo i tecnici sarebbero in grado di interpretarlo correttamente. Al contrario, utilizzando un tipo custom come Order Number, si elimina ogni barriera di comunicazione tra il team tecnico e quello di business. Ciò riduce notevolmente il rischio di fraintendimenti e di errori nella produzione di codice non conforme alle specifiche.
Modellare l’Aggregato in relazione alla realtà
Quando modelliamo un Aggregato, ossia il modello di business che vogliamo risolvere, è fondamentale rimanere il più possibile fedeli alla realtà. Come già sottolineato, avere un linguaggio comune tra i membri del team è essenziale. Ovviamente, dovremo semplificare alcuni concetti, poiché replicare completamente un modello reale all’interno del nostro codice non è possibile. Per evitare che il nostro modello diverga troppo dalla realtà, è importante creare aggregati il più piccoli possibile, cercando di restare il più vicino possibile alla situazione concreta. Un po’ come considerare un processo di business complesso come una figura geometrica, di cui non possiamo calcolare la superficie in modo preciso, se non suddividendola in molteplici parti che integreremo per ottenere un risultato finale che, pur non essendo perfetto, sarà comunque molto vicino alla realtà.
In questo modo, riusciremo a semplificare e risolvere il problema senza perdere troppo in termini di realismo.
Infine, ogni Domain Event deve contenere l’ID dell’aggregato a cui appartiene, e, se presenti, l’ID delle operazioni correlate. Poiché queste proprietà sono ripetute in ogni Domain Event, è consigliabile raggrupparle in una classe DomainEvent. Questo approccio non solo semplifica la scrittura dei Domain Event, ma rende anche immediatamente comprensibile, osservando il codice, se l’oggetto in questione rappresenta un Domain Event.
Chi può sottoscrivere un Domain Event?
A questo punto, è fondamentale chiedersi quali siano le parti interessate a sottoscrivere un Domain Event e chi ne sia legittimato a farlo. Essendo un elemento che appartiene intrinsecamente al dominio, un Domain Event non può e non deve uscire dal nostro Bounded Context!
Come abbiamo visto nell’immagine relativa al pattern CQRS/ES, il Domain Event ha la funzione di aggiornare il nostro Read Model, ovvero quella parte di dati che gli utenti della nostra applicazione andranno a interrogare per prendere decisioni. In un sistema distribuito, queste informazioni potrebbero essere duplicate e replicate in vari Read Model, ognuno appartenente a Bounded Context differenti e, potenzialmente, a microservizi differenti, cioè su database separati.
Ma come facciamo a mantenere aggiornati tutti questi Read Model che non appartengono al nostro Bounded Context? La risposta del programmatore pigro potrebbe essere: “Il Domain Event”. Eppure, se non gestito correttamente, il sistema rischia di trasformarsi rapidamente da distribuito a una sorta di “Big Ball of Mud”, un sistema disorganizzato e difficile da manutenere.
Condividere un Domain Event con altri Bounded Context comporta un errore semantico. In pratica, si sta condividendo un linguaggio tipico di un Bounded Context con un altro che potrebbe non condividere lo stesso linguaggio. Inoltre, nel Domain Event potrebbero esserci informazioni che non dovrebbero essere condivise al di fuori di questo contesto.
Tuttavia, l’errore non riguarda solo la semantica, ma anche l’implementazione. Come abbiamo discusso nella parte 4 di questa serie, in relazione alle Evolutionary Architectures, quando due parti di codice condividono qualcosa, si genera un accoppiamento. Questo compromette la possibilità di evolvere indipendentemente, impedendo a ciascuna parte di adattarsi ai cambiamenti senza influenzare l’altra.
Gli aggregati sono una rappresentazione semplificata del problema di business da risolvere. Poiché i problemi di business sono mutevoli e legati agli esseri umani, prima o poi questi evolveranno, rendendo il nostro aggregato obsoleto. Non si tratta di un errore iniziale di modellazione o di una prematura ottimizzazione, ma di un processo naturale: le cose cambiano! Questo concetto è in linea con l’idea di antifragilità di Taleb, che abbiamo già toccato parlando di Architetture Evolutive.
La vera sfida non è costruire un sistema perfetto, ma uno che possa evolvere e adattarsi ai cambiamenti. Condividere un Domain Event va esattamente contro questa filosofia, impedendo l’evoluzione autonoma dei singoli Bounded Context.
Prima di essere considerato un errore semantico, questo comportamento è un errore architetturale. Se il contratto con cui scambiamo informazioni tra modelli è lo stesso che utilizziamo internamente per mantenere la coerenza tra Domain Model e Read Model, non potremo modificare il nostro aggregato liberamente. Modificare l’aggregato implicherebbe modificare il contratto di comunicazione con altri Bounded Context, costringendoci a notificarli e aggiornarli, e se si tratta di un’architettura a microservizi, a pubblicare le modifiche in concomitanza con il Bounded Context modificato. In caso contrario, la comunicazione fallirebbe a causa della variazione del Domain Event condiviso.
In pratica, questa gestione rischia di portarci verso la complessità dei sistemi distribuiti, combinata con i limiti di un monolite accoppiato, creando la perfetta Big Ball of Mud.
Integration Event
Come avvisiamo il “resto del mondo” che lo stato del nostro Bounded Context è stato modificato? Utilizzando un Integration Event, che, dal punto di vista tecnico, è identico al Domain Event, ma contiene informazioni che possono essere condivise e sono espresse in un linguaggio comune a tutti i Bounded Context del nostro sistema.
Ma se i dati del Domain Event e dell’Integration Event sono esattamente gli stessi? Non importa, pubblichiamo comunque un Integration Event, perché è molto probabile che, prima o poi, il Domain Event cambierà. In quel caso, potremo modificare il Domain Event senza compromettere la comunicazione con gli altri contesti, continuando a emettere lo stesso Integration Event all’esterno, senza interrompere la condivisione delle informazioni con il resto del sistema.
In questo modo, garantiamo l’indipendenza delle diverse parti del nostro sistema, che potranno evolvere liberamente, senza dover dipendere dalle modifiche degli altri contesti.
Versioning
Cosa accade se, a causa di una nuova richiesta, il nostro Domain Event deve subire una modifica? Ad esempio, se dobbiamo aggiungere o rimuovere una delle proprietà?
Innanzitutto, è fondamentale stabilire se si tratta effettivamente di una variazione che non altera il significato del Domain Event. In questo caso, basterà aggiungere delle proprietà senza compromettere il concetto di business espresso. In tal caso, avremo una vera e propria modifica del Domain Event, ovvero una nuova versione. Se, invece, le modifiche sono abbastanza significative da cambiare il significato semantico dell’evento, allora dovremo trattarlo come un nuovo Domain Event, probabilmente con un nome diverso, che rifletta il nuovo intento del business.
Detto ciò, è importante sottolineare che un Domain Event non dovrebbe mai essere modificato. Le ragioni sono sia semantiche che tecniche. Semantico, perché il Domain Event rappresenta un concetto di business, e desideriamo che questo concetto rimanga invariato nel nostro EventStore e nel Domain Model. Tecnico, perché il Domain Event viene serializzato e successivamente deserializzato. Modificare la sua struttura dopo averlo salvato potrebbe impedire il recupero degli eventi dall’EventStore, con il conseguente rischio di non riuscire a ricostruire lo stato del nostro aggregato al momento della deserializzazione.
Come risolvere questa situazione? Versionando gli eventi. Avremo quindi versioni del Domain Event (V1, V2, … Vn) che evolvono nel tempo. Tuttavia, il significato del business deve rimanere invariato; in caso contrario, il nome dell’evento dovrà essere cambiato. Quando ci sono più versioni dello stesso evento, sarà necessario prevedere nel nostro codice gli handler per ciascuna versione, oppure un unico handler in grado di gestirle tutte, valorizzando le proprietà mancanti con valori di default quando necessario. La gestione del versioning è una tematica complessa; per approfondire, consiglio la lettura del libro “Versioning in an Event Sourced System” di Greg Young.
Conclusioni
Da un punto di vista pragmatico, quando devo condividere informazioni tra Bounded Context differenti, che appartengono a microservizi diversi, la tentazione di farlo tramite un oggetto già esistente, come un Domain Event, è forte. Non dovrei far altro che aggiungere un nuovo Event Handler al medesimo topic e il gioco sarebbe fatto.
Tuttavia, questo approccio non comporta solo un errore semantico, ma anche una condivisione di informazioni espresse in un linguaggio tipico di un Bounded Context, con un altro Bounded Context che potrebbe non comprendere lo stesso linguaggio. In altre parole, non stiamo rispettando il principio dell’Ubiquitous Language. Inoltre, in un Domain Event, che è un oggetto parte del Domain Model, potrebbero esserci informazioni riservate che non devono essere condivise al di fuori del Bounded Context stesso.
Non si tratta soltanto di un errore semantico, ma di una questione architetturale: quando due parti del sistema condividono un oggetto, in questo caso un Domain Event, esse diventano accoppiate tra loro. Quando una di queste funzioni deve essere modificata, l’altra sarà costretta a seguirla, compromettendo l’indipendenza dei microservizi coinvolti. Immaginate di dover rilasciare una nuova versione del microservizio dopo aver implementato una feature che ha modificato il Domain Event, senza avvisare i sottoscrittori. Le implicazioni in termini di comunicazione e aggiornamenti diventano notevoli.
Anche se inizialmente le informazioni scambiate sono le stesse presenti nel Domain Event, il consiglio è di creare un Integration Event e condividerlo. Con un piccolo sforzo, otterrete la libertà di modificare il vostro Domain Model come desiderate, senza la necessità di coordinare ogni cambiamento con altri sistemi. E, come si sa, la libertà non ha prezzo!
Nel prossimo articolo vi parlerò delle architetture di tipo Event Driven e delle loro caratteristiche più importanti.