
Agile Venture Vimercate 2019
Sabato 8 Giugno si è tenuto un nuovo appuntamento del circuito Italian Agile Venture presso il palazzo Nokia, sito all’interno del polo Energy Park.
Tema centrale della giornata è riassumibile in due parole: dev ops. Anzi, meglio una parola: DevOps.
Che cosa s’intende per DevOps?
Per molti è una nuova figura professionale, per altri un insieme di pratiche e metodologie, forse entrambi.
In un contesto di sviluppo software agile, che ruolo gioca?
Che contributo può dare affinché si continui a produrre, rilasciare valore nella maniera più rapida ed efficiente possibile?
Scopriamolo assieme ripercorrendo la giornata attraverso il racconto del keynote e di alcuni tra tutti gli interessantissimi talk proposti.
Mattino
Fabio Ghislandi, presidente dell’Italian Agile Movement nonché partner di Intré, ha introdotto la giornata ringraziando Nokia e gli sponsor che hanno reso possibile l’evento e ricordando gli imminenti appuntamenti del circuito Agile Venture:
- La conferenza Working Software, il prossimo 3 Luglio a Milano, Vodafone Theatre.
- PO camp, dal 6 al’8 Settembre.
- L’annuale edizione degli Italian Agile Days che quest’anno si terranno a Modena l’8 ed il 9 Novembre.
Che la conferenza abbia inizio!
Di seguito il programma mattutino.
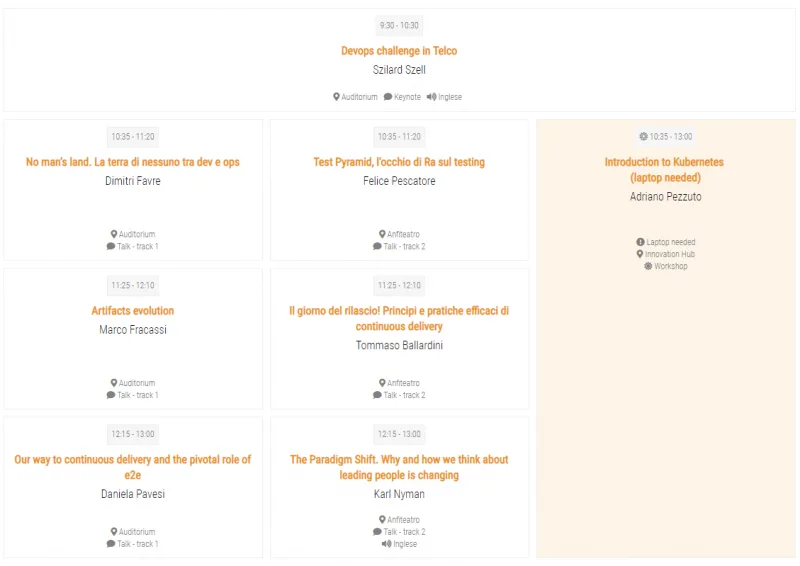
Keynote: DevOps challenge in Telco
Szilard Szell, DevOps Change Agent, SAFe SPC, Test Coach nonché presidente dell’Hungarian Testing Board, ha raccontato come Nokia abbia affrontato, e sta affrontando la sfida al cambiamento verso una cultura DevOps.

dig
Quali sono le tecniche, gli strumenti e i processi che i team agili devono mettere in atto in un contesto di Automated Everything laddove l’automatizzazione NON è un’opzione?
E soprattutto, come fare affinché si abbia un continuo rilascio di valore?
Ricordiamo con una delle tante immagini quello che è il ciclo di attività DevOps, meglio conosciuto DevOps loop.
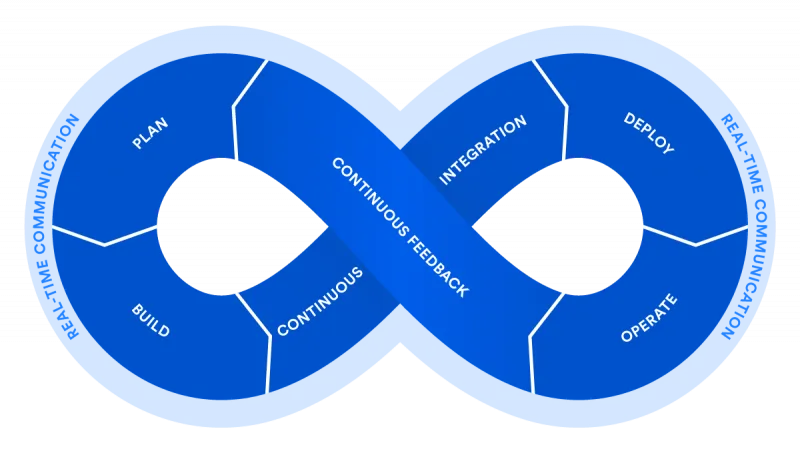
DevOps per Szilard non è una mentalità, piuttosto un comportamento. Meglio, un insieme di comportamenti.
Ma come possiamo tracciare il percorso da seguire affinché l’azienda cambi, integri al meglio queste nuove pratiche?
Ci vengono in aiuto i 3 principi DevOps, meglio conosciuti come The Three Ways, di Gene Kim, figura autorevole in tema di rivoluzione dell’IT. Questi principi sono utili nel guidare un’azienda nella propria trasformazione:
The first way: Systems Thinking
Si enfatizza la necessità di concentrarsi sull’intera linea di business, e quindi su un’ottimizzazione complessiva del flusso di valore, cosa che non passa necessariamente per l’ottimizzazione di un silos o dipartimento specifico.
Come precedentemente scritto, non dimentichiamoci che l’obiettivo è quello di ottimizzare l’intero processo di creazione di una soluzione: dalla sua idea alla sua messa in esercizio, quindi un flusso continuo di valore.
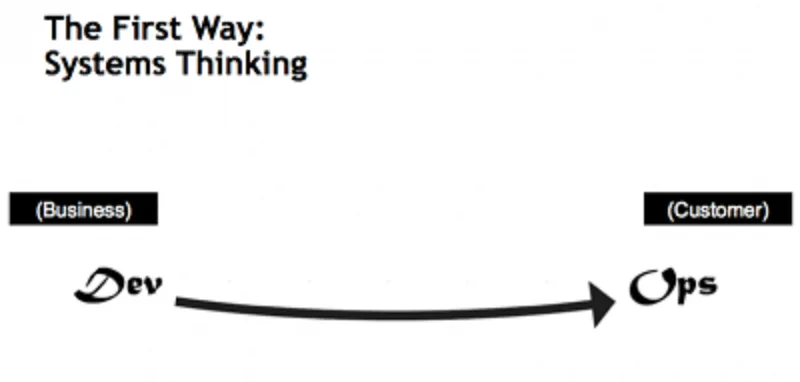
Il focus è sui centri di lavoro, i work center, i quali non possono essere ottimizzati oltre il livello attuale se ciò dovesse andare a scapito del processo globale, ovvero avere un degrado nel flusso del valore, la Value Chain.
La logica è quella pull di lean: sono i work center a valle a prendersi in carico una nuova attività, evitando quindi una situazione in cui due centri di lavoro adiacenti lavorino a velocità disallineate, perché si andrebbe a creare un inutile sovrabbondanza di attività in Ready-to-Pull.
Che risultato porta questo primo principio?
Responsabilizza i work center nella gestione dei difetti, sia di processo che di lavorazione, senza la presunzione che il problema verrà risolto da qualcun altro in qualche modo.
Inoltre, come già evidenziato, porta ad un’ottimizzazione complessiva del flusso di valore, attraverso una comprensione sempre più profonda dei processi ed evitando di sprecare risorse nell’ottimizzazione delle singole stazioni senza tener conto del disegno complessivo.
The second way: Amplify Feedback Loops
L’enfasi si sposta sul feedback, o meglio come poter migliorare il ciclo di feedback affinché sia il più rapido ed efficace possibile.
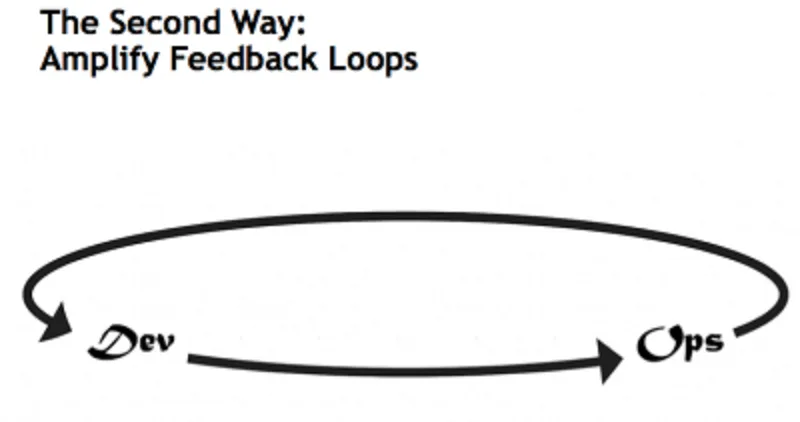
Per migliorare i propri processi è indispensabile quindi che i feedback arrivino velocemente e che l’origine sia la più significativa possibile, andando a coinvolgere tutti gli attori interessati.
A tal proposito, Szilard ha ricordato come in Spotify siano stati predisposti dei monitor sui quali proiettare i feedback degli utenti finali.
Vien da sé che il secondo principio ci aiuta a rispondere più adeguatamente alle esigenze dei clienti, esterni o interni che siano, velocizzando i feedback in modo da aumentare la conoscenza complessiva sugli obiettivi da raggiungere e su cosa è realmente importante focalizzarsi.
The third way: Culture of Continual Experimentation And Learning
Un’azienda che vuole cambiare deve avere la necessità di creare una cultura aziendale in grado di sperimentare continuamente, considerando il fallimento alla base dell’apprendimento e dell’abbattimento dei rischi, e focalizzarsi sulla pratica e sulla ripetizione, ritenendole indispensabile per padroneggiare le attività.
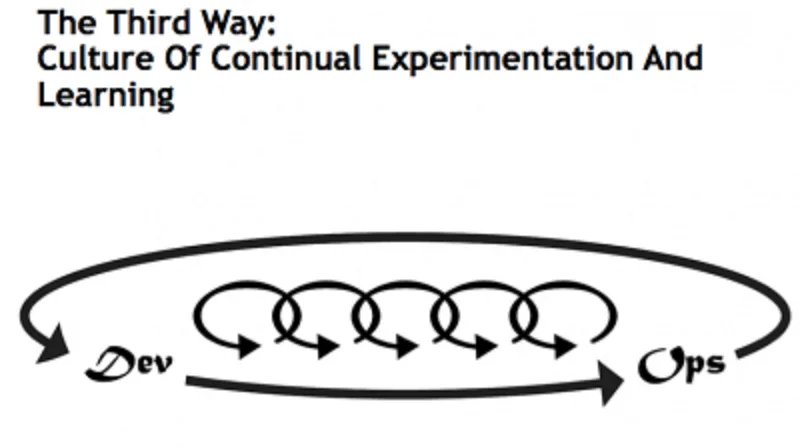
Questo terzo principio porta a benefici rilevanti che vanno dalla migliore ripartizione del lavoro, a incentivi basati sull’assunzione dei rischi, fino all’approccio di introdurre volontariamente piccoli difetti (ricordate: siamo in regime di micro-esperimenti) per testare la resistenza dell’intero processo.
Come Nokia ha quindi affrontato la sfida e di conseguenza riorganizzata? Szilard ha mostrato una interpretazione di Nokia del DevOps loop:

dig
Per ognuna delle fasi temporali Continuous Integration, Monitoring, Delivery e Deployment Szilard ha spiegato come Nokia abbia riorganizzato risorse e processi.
Ma in questa configurazione di continuous everything, di quanti ambienti di deploy è necessario avere bisogno?
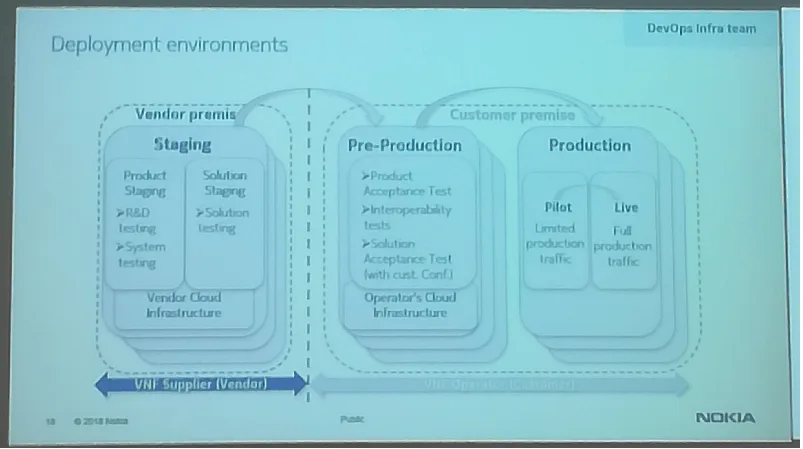
Ricordando che DevOps è un comportamento più che una mentalità, Szilard ha fornito una classificazione, una topologia dei possibili team che si potrebbero organizzare in questo contesto:
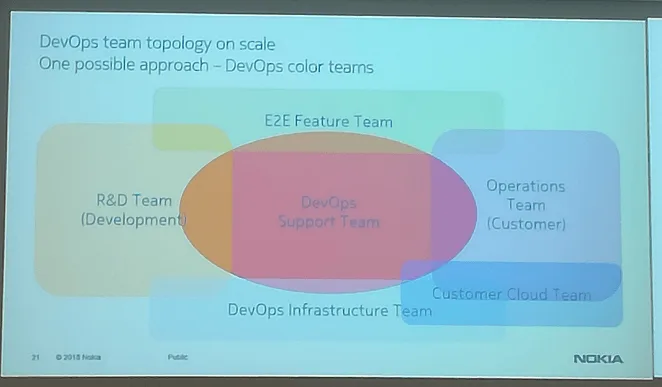
E soprattutto, cosa NON è DevOps:

Assistere ad un talk o addirittura ad un keynote durante il quale non si portano solo nozioni e concetti ma anche proprie esperienze ritengo essere sempre un’esperienza utile, oltre che interessante. Soprattutto quando personalmente non si hanno le idee chiare sulla tematica trattata.
A nome di tutti i presenti in sala, grazie Szilard.
No man’s Land. La terra di nessuno tra DEV e OPS
Dimitri Favre, agile & business coach presso Inspearit, è giunto a Vimercate portando sul tavolo una sua riflessione sul mondo DevOps.
Anche lui, come il sottoscritto, ha in testa mille domande e dubbi, e spera di trovare alcune risposte 🙂

Dimitri non si sente un DevOps, bensì un dev, uno sviluppatore. E’ il suo mestiere, ciò che ha sempre fatto. E probabilmente morirà come tale.
Noi sviluppatori vediamo ops come un sistemista. Qualcuno che è dall’altra parte di un campo di battaglia dove ci si scontra lanciandoci una bomba sempre pronta ad esplodere, che è il sistema, il software.
Vuole però fare luce, cercare di diradare la nebbia generata da questo termine che fonde i 2 mondi in un unico, DevOps.
Dev vs Ops, dunque.
Due eserciti che sono in continua guerra, su un campo di battaglia dove giace un soldato che ne porta le conseguenze.
Quel soldato, che nel film dal quale Dimitri ha preso ispirazione per il titolo del suo talk, si chiama Tzera.
Tzera è nel nostro caso il sistema, martoriato dalle continue esplosioni di questa bomba che viene continuamente rimbalzata tra le 2 parti.

Uno sviluppatore è per il cambiamento continuo, vuole continuamente fare sue nuove tecnologie, framework, linguaggi, E di conseguenza modificare il software.
Il sistemista è per la stabilità. Tutto funziona e non crea problemi. Perché cambiare?
Come è possibile quindi che un DevOps accomuni questi 2 mondi così diversi?
Badate bene, forse DevOps non è una nuova figura professionale, non è uno sviluppatore che sa fare qualcosa lato sistemistico o viceversa.
Piuttosto…
Una mentalità che si porta dietro pratiche, dopotutto lavoriamo in un contesto di continuous everything (come spiegato da Szilard durante il suo talk).
E’ impensabile utilizzare un solo framework o tool per il nostro progetto.
Esistono, per ogni fase del ciclo di sviluppo software, decine e decine di tool diversi.
Di fatto questa è una conseguenza dell’evoluzione delle architetture software, da quella Spaghetti-oriented degli anni ’90 (o Copy & paste) alla Ravioli-oriented dei nostri tempi (o architettura a microservizi).
Il software è più complesso, la sua realizzazione non è mai stata tanto semplice quanto complicata allo stesso tempo. Idem per la sua manutenzione (oggigiorno un sistemista deve imparare a scrivere script per qualunque cosa…).
In questo dominio, l’effetto farfalla è dietro l’angolo.

Tanti tool, tanti framework.
E come sviluppatori, li vogliamo conoscere ed utilizzare tutti.
Perché?
Beh, in primis perché siamo dei nerd :), in secondo luogo perché siamo una sorta di fashion-victim.
“Conosci Ansible? E’ l’ultimo grido in ambito di sviluppo pipeline di continuous integration.”
“Ok, lo utilizzerò”

Ma Dimitri ci ricorda che ciò che oggi è di moda, domani sarà legacy.
Tutti questi tool che usiamo nel nostro progetto, quanta ulteriore frizione genera tra dev e ops?
Ancora una volta, DevOps è una mentalità, un assieme di pratiche e comportamenti AGILI legati alle infrastrutture.
DevOps va inteso quindi come un nuovo approccio per creare un ambiente “frictionless” nel quale l’implementazione di servizi digitali fluisce senza problemi dal concetto iniziale all’utente finale.
Magari velocemente, magari automatizzando tutto. Portando ad un fallimento totale del progetto. Attenzione quindi!
Ancora una volta, DevOps è una mentalità, proprio come l’agilità.
Meglio ancora:
Capita che molte compagnie abbracciano sì la cultura DevOps ma solo perché va di moda, senza peraltro cercando di essere agile (team DevOps in progetti Waterfall…).
DevOps è più una buzzword piuttosto che come mentalità.
Tornando al campo di battaglia, un team DevOps viene spesso visto come una truppa dell’ONU che, in questa terra di nessuno, ha il compito di mediare una pace cercando di accontentare un po’ tutti.
E il software è come un soldato disteso su di una mina pronta ad esplodere.
Per rendere l’idea, Dimitri ha portato l’esempio di una compagnia che spese più di 1.000.000 di dollari per sviluppare un sistema di Integration Testing.
Fantastico.
Peccato che tale sistema non venne mai utilizzato, nonostante il team DevOps avesse avvertito che per completare il primo setup ci sarebbero voluti 45 giorni di calendario.
Cosa impariamo da questa vicenda?
- L’unica ragione convincente per Devops è ridurre il costo di transazione associato al rilascio in produzione (e abilitare il Continuous Release)
- L’unica ragione convincente per Continuous Release è consentire loop di feedback più brevi e rapidi (ed è significativo solo se raccogli un feedback e agisci di conseguenza)
- L’unico modo per ridurre il costo della transazione associato al rilascio in produzione è lasciare che i team di sviluppo conoscano il sistema target del software e che lavorino assieme
E comportarsi come se fossero il solo ed unico responsabile della salute del sistema (sviluppo, test o produzione).
E l’unico modo per ottenere tutto ciò è portare dev e ops nella terra di nessuno…insieme! Come un DEV + OPS team.
E permettere loro di costruire l’infrastruttura senza attriti in cui l’implementazione dei servizi digitali fluisce agevolmente dall’idea all’utente finale.
I miei complimenti Dimitri, hai portato la voce di molti che, come me, hanno idee confuse in merito alla parola DevOps.
Anche io come te sono uno sviluppatore e spesso mi sono ritrovato nelle tue riflessioni, e grazie al tuo intervento ho avuto la risposta a molte domande.
A questo link trovate le slide dell’intervento, il cui titolo è inspirato dall’omonimo film.
Il giorno del rilascio! Principi e pratiche efficaci di continuous delivery
Tommaso Ballardini, backend specialist presso MIA-platform ha raccontato l’esperienza acquisita durante la messa a punto del loro processo di Continuous Delivery.
Che cosa vuol dire Continuous Delivery per Tommaso?
L’abilità di portare cambiamenti in produzione nel modo più sicuro e veloce possibile.
Sembra una grande impresa, realizzabile da giganti come Amazon, Facebook o Google. Invece tutti noi possiamo realizzarla, applicando PRINCIPI E PRATICHE.
Perché pensare ad un sistema di Continuous Delivery?
Per affrontare quella che per la maggior parte, se non la totalità degli sviluppatori, è la più grande paura. IL GIORNO DEL RILASCIO
Come affrontare questo fatidico giorno? Meglio un unico rilascio di tutte le modifiche apportate al codice, o forse è meglio rilasciare spesso ma più facilmente?

Tommaso ha spiegato i diversi ambienti di rilascio organizzati in MIA platform (in ordine di importanza):
- Produzione: il codice e quindi l’applicazione aggiornata è utilizzata dal cliente
- Staging: il codice ha passato una prima fase di test e la validazione da parte del P.O.
- P.O. Acceptance: l’applicazione con le modifiche deve essere validato dal P.O.
Ogni team organizza il lavoro in sprint di durata settimanale.
Durante lo sprint planning il P.O. valida le nuove funzionalità da implementa.
Il team di conseguenza valuta ognuna delle funzionalità: se sono piccole, si sviluppano e si rilasciano direttamente in ambiente di Staging. Questo permette di lavorare parallelamente sullo sviluppo di altre funzionalità di dimensione maggiore.
E’ importante lavorare avendo sempre gli obiettivi sott’occhio, quindi vengono utilizzate board costantemente aggiornate.
Come sviluppatore, Tommaso deve potersi concentrare sulla scrittura di codice di più alta qualità possibile, ed è per questo che si fanno uso tool al quale demandare il deploy automatico.
Il codice rilasciato viene verificato e validato da script che eseguono test e in caso invalidano la push X nel caso in cui i test non passano. In caso contrario, il codice viene rilasciato in ambiente di Staging dove sarà sottoposto ad ulteriori test.
Tommaso ha poi spiegato come hanno organizzato la pipeline, dal check-out del codice al test end-to-end:
- check-out del codice
- test e build dell’immagine
- push dell’immagine su Nexus
- deploy su tutte le macchine
- esecuzione dei test end-to-end
Per gestire al meglio le versioni del codice rilasciato, è necessaria una politica di versionamento, che in buona sostanza serve per dare un nome al codice.
In sintesi, dato un numero di versione del tipo MAJOR.MINOR.PATCH, va incrementata la:
- versione MAJOR quando si modifica l’API in modo non retrocompatibile,
- versione MINOR quando si aggiungono funzionalità in modo retrocompatibile,
- versione PATCH quando si corregge un bug in modo retrocompatibile.
Sono disponibili etichette aggiuntive per il pre rilascio e i metadati di build come estensioni al formato MAJOR.MINOR.PATCH. Ulteriori approfondimenti a questo link.
Avere il codice così versionato aiuta qualora in produzione emergano bug. Si individua la versione precedente del quale si è certi del funzionamento (i test lo garantiscono) e si esegue un roll-back in pochi minuti, abbassando notevolmente il tempo di disservizio per il cliente.
Di seguito la slide che mostra lo schema di Continuous Delivery adottato da Tommaso e colleghi
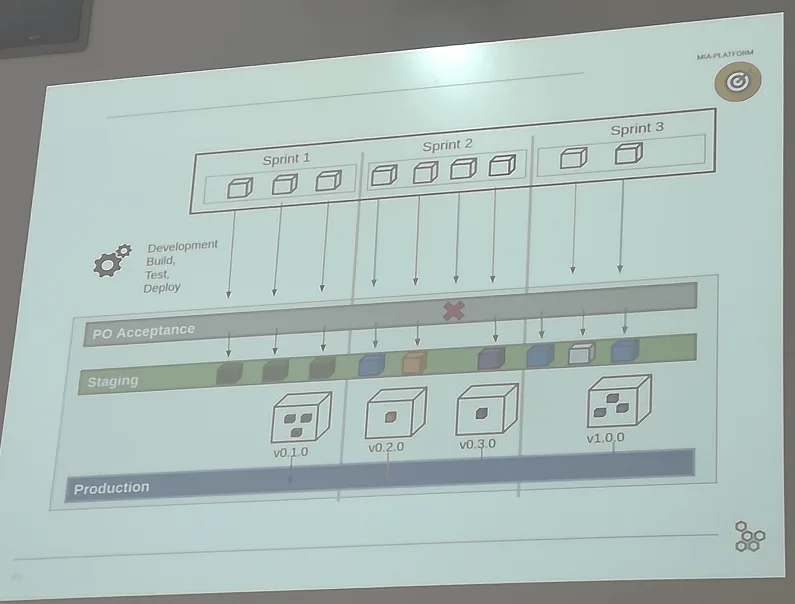
In ultima analisi, avere organizzato delle finestre di rilascio frequenti (sprint di 1 settimana) e un sistema di rilascio incrementale e rapido ha fatto sì che Tommaso e tutti i team in MIA platform non vivano più il giorno del rilascio con ansia e paura, bensì possano affrontarlo come un giorno lavorativo qualunque.
Grazie Tommaso per il tuo tempo, il giorno del rilascio non è più così temuto 🙂
Our way to continuous delivery and the pivotal role of e2e
Daniela Pavesi, sviluppatrice front-end presso lastminute.com ha raccontato la sua esperienza durante un progetto iniziato nel 2016 e tuttora in corso.

Come era organizzata l’infrastruttura aziendale gli anni precedenti?
- 2013: sistemi eseguiti su macchine virtuali, server fisici
- 2014: macchine virtuali, server fisici e primi micro-servizi
- …
- 2016: Kubernetes che gestiscono POD contenenti container Docker. Macchine virtuali e server fisici soppiantati
Nel 2016 quindi, Daniela e il resto del team composto sia da sviluppatori front-end che back-end, 1 UX designer e 1 Product Owner hanno deciso di utilizzare l’ultima infrastruttura (Kubernetes e container Docker) per un nuovo progetto.
Il progetto consisteva nella gestione della pagina del carrello per il check-out degli ordini, con tutta la complessità che nasce dalle svariate combinazioni in ambito prenotazione (volo, volo più hotel, noleggio dell’auto, modalità di pagamento…).
2 applicazioni da gestire, 1 lato front-end e 1 per il back-end, che dovevano interagire con più di 10 microservizi.
Fin da subito, si pensò di organizzare un ciclo di Continuous Integration:
- scrivere unit test
- implementare una GUI test per il front-end (usando mock e PhantomJS)
- organizzare una pipeline in modo tale che venisse eseguita una build ad ogni push (lato sia front-end che back-end)
Inevitabilmente iniziarono a sorgere dei problemi di compatibilità bidirezionali front-end con back-end.
In più la crescente complessità dovuta agli scenari applicativi in continuo aumento portava a lunghe fasi sia di sviluppo che di test manuali, con un conseguente rallentamento sulle tempistiche di release e quindi di effettivo rilascio di valore.
Si decise quindi di evolvere i test Javascript affinché testassero anche il back-end, ma la difficoltà emersa per poca conoscenza aveva portato all’implementazione di test poco stabili. Inoltre ai tempi (2017) era ignoto l’effort per adeguare le pipeline Jenkins.
Soluzione scartata quindi.
Si pensò di adottare un altro approccio. Perché non sviluppare una suite di test in Java sfruttando una libreria di test (basata su Selenium) implementata dal team di Quality Assurance?
La scelta fu azzeccata ed iniziarono ad arrivare i primi risultati, anche perché il codice front-end era stato implementato test-oriented, e cioè per ogni elemento HTML era stato pensato un attributo custom data-test per garantire la reperibilità ed interazione in fase di test end-to-end, indipendentemente da modifiche grafiche che avrebbero alterato completamente la logica invalidando quindi tutti i test precedentemente scritti.
Risultati ottenuti anche grazie alla possibilità di consultare report sull’esecuzione del caso di test, e screenshot delle pagine interessate al test.
Ma l’effort per ogni persona era ancora elevato (si doveva scrivere codice per il front-end più codice Java per il test).
Si è deciso quindi di fare refactoring della suite di test, coinvolgendo anche gli sviluppatori back-end, cercando di ottenere un codice più leggibile e snello. Quale occasione migliore per passare all’utilizzo di un altro linguaggio, magari che desse la possibilità di definire un DSL (Domain Specific Language). Benvenuto KOTLIN!
Vuoi che Kotlin è stato facile da imparare (se arrivi da esperienze in Java), vuoi che c’era forte interesse, Daniela e un collega nel giro di 2 settimane hanno migrato l’intera code base in questo linguaggio.
E oggi?
Le sfide successive per Daniela e il resto del team riguardano l’ulteriore miglioramento delle prestazioni di esecuzione dei test, che comunque sono scese dai 12 minuti iniziali a 3 minuti.
Un’altra sfida riguarda lo scope, cioè cercare di ridurre le dipendenze da altri micro-servizi.
In chiusura dell’intervento sono stati elencati alcuni vantaggi nell’adozione di una suite di test fin da subito per un progetto:
- nessun test manuale in fase di pre-rilascio
- release più frequenti
- debug più veloce
- riduzione dei bug in produzione
Grazie ancora Daniela!
Pomeriggio
Dopo esserci riposati e soprattutto rifocillati (molto apprezzata la combo pizza + panino 🙂 ) è giunto il momento di riprendere la conferenza seguendo altri interessantissimi talk tra quelli proposti:
Test Driven Development (TDD), the XP way
Manuela Munaretto e Loris Ugolini, entrambi collaboratori di XPeppers, hanno proposto un talk tecnico incentrato sul modello di sviluppo software TDD (Test Driven Development) tramite una sessione di live coding in Java di un kata noto quale lo String Calculator.

La scrittura di test prima del codice di produzione consente di avere un design più pulito e disaccoppiato.
Il codice di una suite di test, essendo codice che testa il codice di produzione, ha anch’esso una dignità perciò va mantenuto e rifattorizzato continuamente.
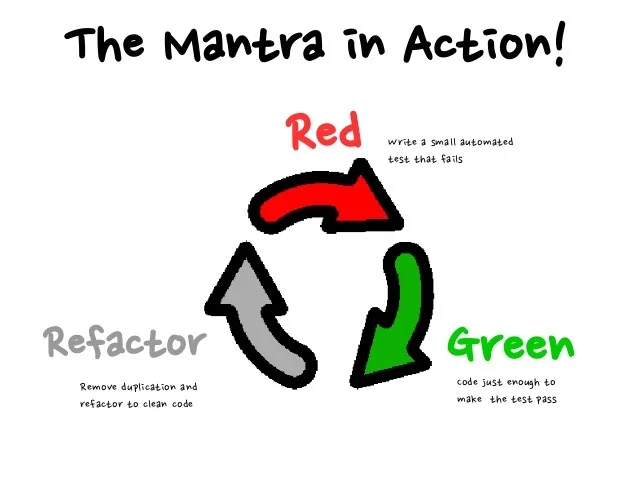
Quando si applica TDD, ricordiamoci perciò sempre il mantra Red – Green – Refactor:
Torniamo al kata scelto da Manuela e Loris.
Il kata è suddiviso in step che aggiungono man mano complessità al programma.
Hanno iniziato dal primo step:
Creare un semplice calcolatore di stringa con un metodo int add (numeri di stringa)
- L’argomento stringa può contenere 0, 1 o 2 numeri e restituirà la loro somma (per una stringa vuota restituirà 0) ad esempio “” o “1” o “1,2”
- Inizia con il caso di test più semplice di una stringa vuota e passa a 1 e 2 numeri
- Ricordati di risolvere le cose nel modo più semplice possibile, in modo che ti costringa a scrivere test a cui non hai pensato
- Ricordarsi di fare refactoring ogni volta che tutti i test passano
Tra le righe si può facilmente riconoscere il mantra del TDD, e l’importanza di pensare alla cosa più semplice possibile ma che porti valore.
Tra un caso di test e il seguente codice di produzione Manuela ha suggerito la lettura del libro Test Driven Development. By example di Kent Beck come punto di partenza per appunto la pratica TDD, spiegato attraverso diversi esempi.
Purtroppo il tempo a disposizione per implementare tutti e 6 gli step del kata mancava, perciò Manuela e Loris hanno dedicato l’ultima parte del loro intervento mostrandoci come implementare, sempre in TDD, un’ulteriore funzionalità legata all’output dello String Calculator, ad esempio in un file .txt oppure in una tabella di un database.
Quale architettura software può venirci in aiuto affinché sia possibile disaccoppiare la logica di business con la tecnologia che c’è all’esterno (scrittura in un file, salvataggio in un db…)?
Nessun problema, la risposta c’è e si chiama architettura esagonale, nota anche come Port and Adapter.
Manuela ha quindi scritto dapprima i test, utilizzando le direttive @InjectMoks e @Mocks della libreria per unit test in Java Mockito, e di conseguenza le interfacce (porte) e le loro implementazioni (adapter).
Grazie Loris e Manuela, un intervento mirato che ha ricordato una volta di più quanto sia importante applicare TDD ad un progetto, ottenendo un codice di produzione il più possibile esente da bug.
Superpoteri e crescita esponenziale dell’organizzazione con “Infrastructure as code”
Carlo Corti e Tommaso Previero entrambi software engineer presso lastminute.com hanno presentato la loro esperienza in merito ai vantaggi ottenuti adottando una soluzione Infrastructure as Code, o IaC.
Tommaso è un esponente del team platform, mentre Carlo è uno sviluppatore, esponente del team prodotto.
Gestiscono diversi microservizi sviluppati utilizzando diversi linguaggi (Java, Kotlin, Python, Go) e gestiti on-premise tramite Kubernetes o virtual machine.
Come ambienti di cloud, utilizzano sia AWS che Azure, e ultimamente Google Cloud Platform, GPC.
Quale infrastruttura scegliere? Dato che parliamo di progetti software, diamo più importanza al team platform o al team prodotto?
Per l’integrazione con l’ecosistema di Google, Carlo e Tommaso hanno spiegato delle difficoltà incontrate quando la gestione è stata demandata al team di sviluppo, quindi team prodotto.
A fronte di una diminuzione del time-to-market avevano riscontrato diversi problemi in termini di gestione e controllo del progetto, vuoi per un’iniziale scarsa conoscenza degli strumenti, vuoi per mancanza di alcuni tool necessari.
Inoltre c’erano difficoltà comunicative con il team platform.
Bisognava cambiare approccio. Magari che rispettasse alcuni vincoli quali:
- utilizzare un linguaggio comune
- un unico ambito
- supervisione da parte del team platform
- 100% di auditing
La soluzione?
Una applicazione, basata su Terraform, scritta in linguaggio Golang e mantenuta con git e GitLab.
Perchè Terraform?
E’ una soluzione Infrastructure as Code con la quale, usando un file strutturato, un semplice pezzo di codice, si è in grado di controllare ogni cosa all’interno della tua infrastruttura: network, risorse, storage, DNS, database, sicurezza, scalabilità, automazione, in poche parole tutto.
Infatti, con il crescente utilizzo di infrastrutture e tecnologie cloud, l’esigenza di una soluzione che non dipendesse esclusivamente da un unico fornitore è diventata sempre più una necessità.
Gli ambienti cloud sono continuamente soggetti a malfunzionamenti e, avendo tutte le uova in unico paniere, diventano molto vulnerabili. Gli IT manager, hanno quindi iniziato a cercare un modo per distribuire i carichi di lavoro tra il cloud e differenti provider per minimizzare l’esposizione al rischio.
Il pezzo mancante in questo puzzle è avere un singolo tool che permetta all’utente finale (che sia l’IT manager come Tommaso o lo sviluppatore come Carlo) di gestire i molteplici ambienti con un set di strumenti standardizzato. Ed ecco Terraform!
Con un’infrastruttura di questo tipo, Carlo e Tommaso hanno ottenuti notevoli risultati in termini di:
- qualità
- costo
- tempo
Nonché aver migliorato di gran lunga la collaborazione tra i 2 team.
Nell’ultima parte del tempo a disposizione, è stata fatta una demo per dimostrare la semplicità e la velocità con il quale creare l’infrastruttura per un nuovo progetto, tutto da riga di comando!
Un talk davvero interessante, che porta sì alla luce le complessità legate alla gestione di un progetto nel mondo odierno ma che offre un bell’esempio di come l’unione possa fare la forza.
Inoltre non avevo mai sentito parlare di Terraform perciò come si suol dire…prendo e porto a casa!
Total Testing in DevOps
Ed eccoci all’ultimo slot di talk.
Ho deciso di seguire un ex-collega, nonché amico Gianni Bombelli.
Permettetemi di fare una digressione.
Avete mai sentito parlare di calcio totale?
E’ uno stile di gioco per cui ogni calciatore che si sposta dalla propria posizione è subito sostituito da un compagno, permettendo così alla squadra di mantenere inalterata la propria disposizione tattica. Secondo questo schema di gioco nessun giocatore è ancorato al proprio ruolo e nel corso della partita chiunque può operare indifferentemente come attaccante, centrocampista o difensore.
Ora pensiamo al DevOps loop.
In tutte fasi del ciclo, dalla pianificazione alla build passando per continuous feedback e continuous integration, che fine ha fatto la parola test? Perché non pensare di applicarlo TOTALMENTE, mantenendo inalterata la struttura? 🙂
Torniamo a noi.
Gianni non parlerà di come scrivere test, test automatici o ottenere coverage tramite casi di test, tantomeno di come realizzare pipeline di continuous integration.
In questo fantastico mondo DevOps dove tutto è automatizzabile, continuous integration, continuous feedback, continuous everything…che fine hanno fatto i test? Sono solo un passo della pipeline di build?
Riprendendo il secondo dei 3 principi DevOps, Amplify feedback loops, ovvero come poter migliorare il ciclo di feedback affinché sia il più rapido ed efficace possibile…servono feedback di valore.
E come possiamo collezionare feedback? Facendo test!
Sappiamo che esistono test di unità, o unit test, scritti dallo sviluppatore pensando a come dovrebbe funzionare l’applicazione.
Esistono i test funzionali, o functional test, scritti dal product owner e anche da altri stakeholder del progetto.
Esistono anche altre tipologie di test:
- usabilità
- performance
- carico/stress
- sicurezza
Gianni dà una sua versione del DevOps loop, per capire come poter inserire i test in tutte le sue fasi

Branch, code, merge
Come sviluppatori, adottiamo tutti o quasi una strategia di branching per mergiare il nostro codice. Ma ci siamo mai preoccupati di testare la bontà del modello di branching adottato?
Discutere se va bene, o può aver senso cambiarlo.
Automated build
Il nostro sistema di build automatico va bene? Potremmo scrivere dei functional test che si eseguono in automatico e avvisano in merito al successo o meno della build.
Potremmo ottenere ulteriori feedback quali:
- usabilità: è facile utilizzare il sistema di build?
- performance: quanto tempo impiega il sistema nel realizzare una build?
- carico: come si comporta il sistema quando si avviano più build in parallelo?
Un’ulteriore riflessione: quando implementiamo una pipeline in Jenkins, scriviamo del codice perciò…perché non testare quel codice? Perché non provare a scrivere la pipeline in TDD 🙂
Delivery
Lo schema di versionamento del codice è efficiente? Distinguiamo facilmente pacchetti validi da quelli non validi? I pacchetti hanno un checksum per verificare che non siano corrotti?
Potremmo pensare di scrivere dei functional test che danno feedback e rispondono alle domande.
Configuration management e deploy automation
Quando deployamo il nostro software, clicchiamo un bottoncino magico che fa partire il processo.
Può avere senso scrivere dei functional test e raccogliere feedback in merito al risultato del deploy:
- con una verifica manuale (click del pulsante): potremmo essere avvisati in merito ad eventuali fallimenti
- con una verifica (almeno manuale) potremmo provare il rollback di configurazioni o di versioni
Inoltre potrebbe aver senso eseguire dei test di usabilità, performance e sicurezza
Per configurare il nostro sistema quasi sicuramente usiamo dei tool come Ansible che mettono a disposizione un DSL (domain specific language) , quindi ha senso pensare di scrivere unit test.
A tal proposito, Gianni curerà il talk Test-Driven Infrastructure with Ansible alla conferenza Working Software, prossimo evento del circuito Italian Agile Venture di natura prettamente tecnica che si terrà il 3 Luglio a Milano, Vodafone Theatre.
Monitor
Quando eseguiamo un deploy o eseguiamo dei test automatici, potrebbe essere utile avere feedback in merito a quale porzione di codice rallenta il sistema o quella contenente più bug.
Plan
L’applicazione sul quale lavoriamo ha un’interfaccia grafica? Potremmo studiare l’esperienza utente della applicazione e testarla prima di procedere al design.
Qualora volessimo implementare una nuova funzionalità, si potrebbe testarla con sondaggi rivolti agli utenti o magari progettando una landing page da consegnare all’utente.
Un intervento davvero interessante quello di Gianni, che riporta il focus su un’attività, quella del test, che può facilmente venire accantonata quando parliamo di DevOps.

E soprattutto, non dimentichiamoci mai di

Conclusioni
Fabio Ghislandi ha chiuso la giornata di conferenza ringraziando tutti coloro che hanno reso possibile l’evento (sponsor, speaker e tutti i partecipanti) e ricordando i prossimi impegni del circuito Agile Venture.
Anche per me è giunto il momento di salutarti caro lettore, dandoti appuntamento al prossimo articolo o perché no, di persona al prossimo evento 😉