
GUID e SHA-1 distrutti da 5 righe di codice
In questo articolo a cura di Francesco Sacchi si parlerà dell’efficacia di alcune tecniche di generazione di id univoci all’interno di un’applicazione.
Verranno presentati ed analizzati tre metodi, due forniti da terze parti ed uno custom.
Affidarsi a qualcosa di già pronto o implementare ad-hoc una soluzione?
Ricordando che nell’ultimo paragrafo Riferimenti trovate tutti i link di approfondimento, vi auguriamo buona lettura.
Generazione di id: usare funzioni già pronte o metodi ad-hoc?
Nello sviluppo di un’applicazione prima o poi capita di dover generare degli identificativi univoci e molto spesso la scelta ricade su librerie che generano un UUID, o GUID (Globally Unique Identifier) perché forniscono una soluzione rapida al problema.
Tali funzioni possono essere implementate in maniera differente ma in sostanza sono in grado di generare una stringa alfanumerica a lunghezza fissa con probabilità molto bassa di ripetizioni, quindi praticamente univoca.
Un’altra opzione altrettanto semplice è quella di usare una funzione di hash sul dato a cui bisogna assegnare l’id: similmente ai GUID, queste funzioni implementano un algoritmo che, dato un input formato da n byte, restituisce in output una stringa alfanumerica a lunghezza fissa con probabilità molto bassa di essere ripetuta.
La semplicità di queste soluzioni pronte ha però delle controindicazioni.
Generazione di ID: un esempio pratico in Node.js
Si consideri il seguente problema: un elenco di utenti per cui occorre generare un id. I dati di un utente potrebbero somigliare a qualcosa del genere:
{"name":"Francesco","lastName":"Sacchi"}
Utilizzo di moduli di terze parti
Un UUID potrebbe essere generato tramite il seguente codice (l’ultima riga è l’id restituito dalla chiamata del metodo uuidv1()):
> const uuidv1 = require('uuid/v1');
> uuidv1()
14fff1b0-3203-11ea-883f-cb004995576f
Per quanto riguarda le funzioni hash, generare un id tramite la funzione di hash SHA-1 è altrettanto semplice:
> const sha1 = require('sha1');
> sha1('{"name":"Francesco","lastName":"Sacchi"}')
0b99204c25fe85a2da6cb3d39896306d0db58b47
Generare un id tramite UUID o SHA-1 solleva alcune questioni:
- Si deve aggiungere al progetto un’ulteriore dipendenza.
- Il calcolo dell’UUID o SHA-1 richiede un certo sforzo computazionale.
- C’è sempre una seppur piccola possibilità di collisione e quindi potrebbe capitare di ottenere identificativi uguali.
Di seguito troviamo un’alternativa, proposta da Francesco, che puo’ essere vista come spunto o provocazione: al prossimo GUID o HASH fermiamoci a pensare se sia veramente necessario.
Utilizzo di una funzione implementata ad-hoc
Generare un ID univoco può essere relativamente semplice.
L’implementazione prevede di sfruttare l’ora di sistema che è di fatto un progressivo numerico. Al fine di tutelarsi dall’utilizzare due volte la stessa data, la funzione legge la data fino a quando questa non cambia almeno una volta e utilizza quest’ultimo valore. Una successiva chiamata, per quanto rapida, dovrà comunque aspettare un nuovo valore.
Di seguito un codice di esempio:
const { performance } = require('perf_hooks');
function generateId(){
const reference = performance.now();
let uniqueId = performance.now()
while(uniqueId == reference){
uniqueId = performance.now();
}
return uniqueId;
}
Questa implementazione funziona nell’ambito di un singolo thread. Non è adatta invece se ci sono più thread concorrenti che la usano.
Approcci di generazione ID a confronto
Tornando alle tre controindicazioni dell’approccio UUID/SHA-1 si osservino i seguenti dati di dimensione del bundle e millisecondi per 100.000 interazioni.
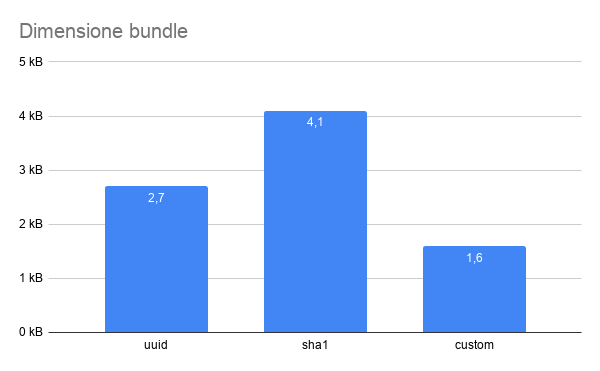
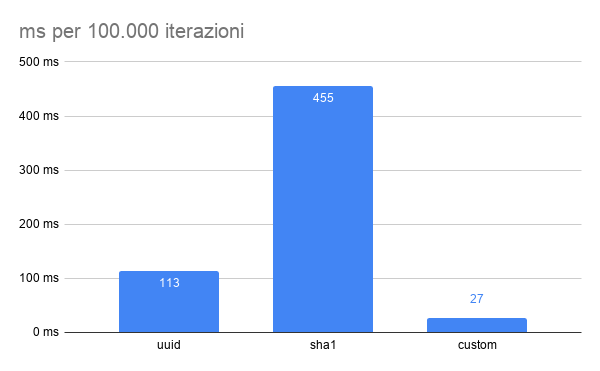
Conclusioni
Per i due approcci, terze parti vs custom, si potrebbero riassumere le seguenti caratteristiche:
| uuid/sha1 | custom |
|---|---|
| tanti byte | pochi byte |
| lenta | veloce |
| potenzialmente potrebbe fallire | funziona sempre |
La soluzione custom è migliore su tutti i fronti. Quando conviene dunque usare guid o hash? Un caso sono i sistemi distribuiti dove non è possibile avere un nodo che garantisca l’univocità dell’id.
Si prenda ad esempio il sistema di controllo di versione git che per ogni commit deve generare un id. Essendo il commit eseguito in locale, potenzialmente senza connessione internet, risulta impossibile verificare, al momento di creazione del commit, che quell’ID non sia già stato utilizzato in un altro commit.
Sfruttando l’algoritmo SHA-1 sul contenuto del commit stesso git riesce a ottenere un ID con una confidenza ragionevole che sia univoco.
In conclusione, a meno che non si stia progettando un sistema distribuito, probabilmente si può fare a meno di utilizzare GUID e hash.