
Giovedì 16 Marzo, presso il centro congressi Lingotto Fiere di Torino, si è tenuta la quinta edizione della CloudConf.
Intré quest’anno era tra gli sponsor per cui Giovedì mattina, armati di tutto l’occorrente per lo stand (proiettore, gadget di vario genere, brochure) e di energia, siamo partiti alla volta della conferenza.
Voglia, energia che si sono un pò affievolite quando, all’arrivo all’ingresso della conferenza, abbiamo trovato un pelino di coda

Nessun problema! Giocandoci la carta speciale sponsor, siamo entrati agevolmente (se tu che stai leggendo eri fra coloro che si sono sorbiti la coda, non odiarci 🙂 ) e ci siamo diretti alla zona a noi riservata per allestire lo stand.

Colui che vedete dietro al banchetto è Emanuele, designer di Intré nonchè responsabile di Thanks Design, una venture di Intré che si pone l’obiettivo di affiancare il cliente nello studio e realizzazione del prodotto seguendo il processo del Design Eye, un modello iterativo incentrato sull’utente e composto da 4 fasi:
- ricerca
- ipotesi
- sviluppo
- test
Quale miglior occasione se non la CloudConf per sponsorizzare e parlare di Thanks Design?
Qui il video dell’intervista ad Emanuele ed Alex Mufatti.
Sistemati gli ultimi dettagli, tutto era pronto per accogliere i curiosi al nostro stand e vivere appieno questa giornata.
Mattina
La mattina è stata dedicata a ben 4 keynote, inframezzati da 1 ora abbondante di pausa a base dell’immancabile caffè accompagnato da una sorta di mini sachertorte personalmente molto apprezzate.
Tutti e 4 i keynote si sono svolti nella “room 500”, la sala più grande delle 3 dedicate per l’evento.
A rompere il ghiaccio è stato Gabriele Mittica, uno degli organizzatori della conferenza, che ha brevemente presentato la giornata di questa edizione della Cloud Conf e nell’occasione ha annunciato la prima edizione di una nuova conferenza, la ApiConf, in data 15 Giugno, stesso città, stessa location, stessa ora 🙂

Orchestrating Least Privilege
Diogo Monica, security lead per Docker, ci ha parlato dell’importanza degli orchestrator abbastanza sicuro in un sistema distribuito.
Ma che cos’è un orchestrator?
Diogo ha cercato, personalmente riuscendoci, di spiegarne il significato con un continuo parallelismo con la classica orchestra musicale, definendone dapprima i componenti:
- Compositore: colui che scrive la melodia.
- Direttore: colui che coordina tutti i musicisti affinché seguano al meglio la melodia, scritta per ogni strumento.
- Strumento musicale e musicista.
E successivamente provando a rivedere ruoli e compiti in un ambiente a noi un po’ più familiare:
- Un ingegnere che implementa degli script come compositore.
- orchestrator come direttore d’orchestra.
- Microservizi vari, container etc. come strumenti.
Focalizziamoci sul direttore d’orchestra. Che compiti deve svolgere?
Direttore d’orchestra:
– casting
– assegnamento degli spartiti musicali
– gestione delle performance di ogni musicista
– gestione dei tempi musicali
Orchestrator
– node management
– test management
– cluster data reconciliation
– resource management
Ma come un orchestrator può svolgere al meglio i suoi compiti di gestione delle risorse tra i nodi di un sistema distribuito, garantendo un livello di sicurezza accettabile che impedisca attacchi dall’esterno e dall’interno?
Seguendo il principio del least privilege (basato sul concetto di competenza specifica) tale per cui ogni nodo, processo deve avere accesso e controllo alle informazioni e risorse strettamente necessarie al compito ad esso assegnato. No more, no less.Tornando al paragone con l’orchestra, un violinista deve suonare il violino seguendo uno spartito ben preciso.
Diogo ha poi proseguito il suo talk domandandosi e domandandoci: dove siamo oggi? Come possiamo soddisfare il principio del least privilege con il nostro orchestrator?
- Mitigando attacchi esterni
- Mitigando attacchi interni
- Mitigando attacchi Men in the middle
- Mitigando malicious worker
- Mitigando malicious manager
Docker dalla sua, propone come soluzione Swarm, che può intendersi appunto come uno strumento di clustering e di pianificazione per container. Con Swarm, amministratori IT e sviluppatori possono stabilire e gestire un cluster di nodi come un unico sistema virtuale.
Diogo ci ha poi illustrato alcuni comandi relativi a Swarm, come ad esempio
docker swarm init
per inizializzare appunto Swarm creando il primo nodo che automaticamente fa anche da manager.
Successivamente ci ha spiegato la semplicità di aggiunta di nuovi nodi, la gestione della presenza di più manager, e la sicurezza dei dati e della comunicazione di questa rete, garantita dal protocollo TLS che appunto protegge la rete e i nodi da tentativi di attacchi sia interni che esterni.
Altro comando degno di nota che Diogo ha voluto mostrarci è
docker secret create private_token
che crea una chiave privata ma sharata tra i nodi manager e worker, rendendo ancor più sicura la comunicazione.
Insomma, gran bel keynote, condotto magistralmente da un direttore all’altezza. Bravo Diogo!

Machines Are Learning: Bringing Powerful Artificial Intelligence Tools for Developers
Danilo Poccia, technical evangelist per AWS, ci ha parlato di machine learning, dedicando una prima parte del talk alla teoria, per poi concludere con una demo relativa ad alcuni servizi di Amazon AI.
Perchè si è arrivati al machine learning?
Da sempre, l’uomo ha avuto l’annoso problema di elaborare il dato a sua disposizione (di qualunque natura esso sia) per ottenere predizioni sul futuro.
E con che cosa si possono ottenere predizioni? Con un modello.
Danilo ha citato Arthur Samuel, pioniere del computer gaming e dell’intelligenza artificiale, quando nel 1959 realizzò il primo computer, cioè il primo modello.
Può questo modello migliorarsi, crescere, imparare sulla base alla quantità e tipo di dati che deve elaborare?
3 tipi di machine learning:
Negli anni, si sono affinate altre teorie e conseguentemente sono state introdotte altri modelli. Uno di questi, il modello di neural network, si basa sul funzionamento delle interconnessioni dei neuroni del cervello, e tutt’oggi trova grande applicazione nell’implementazione di sistemi di intelligenza artificiale molto complessi.
Concetti e teorie molto affascinanti, che meriterebbero approfondimenti.
Danilo ha concluso il suo keynote con ad una demo relativa ad una applicazione la quale, prendendo in input la foto del famoso dipinto Monna Lisa, restituisce una scheda con i dati della figura (sesso, colore pelle, stato d’animo tra gli altri).

Questo per dimostrare come sia semplice, tramite l’utilizzo di alcuni servizi della suite di prodotto Amazon AI, realizzare applicazioni smart di machine learning in maniera semplice e rapida.
Un talk interessante, che dà molti spunti relativamente allo studio di un campo, quello del machine learning, da tenere in forte considerazione per il nostro futuro.
Qui le slide relative all’intervento di Danilo.
TensorFlow in the Wild (or democratization of Machine Intelligence)
Kazunori Sato, developer advocate per Google Cloud Platform, ci ha parlato di TensorFlow, una libreria open-source sviluppata da Google per lo sviluppo di modelli di neural network.
Kazunori ha esordito chiedendosi che correlazione ci potesse essere appunto tra neural network e deep learning (altro concetto enunciato da Danilo Poccia nel suo keynote).
Breve parentesi: per deep learning si intende una classe di algoritmi di machine learning.
Tornando a noi, la risposta di Kazunori è stata: neural network è una funzione, che può imparare.
Originale, devo ammetterlo.
Come esempio di algoritmo di deep learning che fa uso di TensorFlow, Kazunori ci ha mostrato una pagina web relativa ad un grafico a spirale costituito da puntini arancioni e blu che si colora appunto di arancione e blu in base alle interconnessioni simulate di 3 serie di neuroni.
Dopo aver configurato il numero di neuroni per ogni strato, Kazunori ha avviato l’applicazione mostrandoci come, nel giro di pochi secondi, il software basato appunto su TensorFlow avesse elaborato i dati e colorato man mano tutta l’area in base al processamento live dei dati.

Stupefacente quanto complesso!
Dopo questa breve demo, Kazunori ha continuato a spiegarci dei casi d’uso di questa libreria in diversi campi applicativi mostrandoci filmati inerenti a macchine comandate da software che nella sua architettura fa uso di TensorFlow:
- Classificazione zucchine in base alla loro lunghezza
- Chicken nugget server machine, cioè un braccio meccanico che seleziona pezzi di pollo fritto da posizionare nel piatto.
- Classificazione rifiuti.
TensorFlow for all!
WebHooks: the API Strikes Back
Phil Nash, developer evangelist per Twilio, ha curato l’ultimo dei 4 keynote previsti.
Le API colpiscono ancora!!!
Con quale modo, se non ricordando un titolo di un certo film sulle navi e spazio 🙂 , Phil poteva esordire?
L’intento dell’intervento di Phil è stato di farci riflettere su come, grazie all’uso di webhook, molte API non sono più da intendersi come semplici servizi REST in quanto ci parlano, ci comunicano qualcosa, o meglio ci forniscono dati, informazioni che possiamo usare per scatenare azioni in altre nostre applicazioni.
Phil ci ha elencato diversi servizi a noi noti che fanno uso di webhook:
- GitGub
- Dropbox
- Braintree
- …
Spiegandoci del perchè se ne fa un uso sempre più intenso, quali vantaggi si possono trarre.
Ha poi, come i suoi predecessori, dato spazio ad una demo nel quale ha implementato una semplice webhook, in node.js, la quale reagisce a delle emoji scritte in una chat, con altrettante emoji.
Per tenere traccia di tutte le richieste http eseguite, l’esito delle chiamate, i dati inviati, i tempi e quant’altro, ci ha dapprima mostrato e quindi consigliato l’utilizzo di ngrok.
Un talk ricco di contenuti, riflessioni e spunti, personalmente apprezzato perchè condotto con simpatia ed energia. Bravo Phil!
Qui le star wars slide del keynote.

Lunch time
Dopo i 4 keynote mattutini, la sete di curiosità era soddisfatta, gli stomaci un pò meno per cui ci si è letteralmente piombati sul buffet a base di pizza, arancini e quant’altro.
Tutto ciò che poteva essere commestibile, è stato polverizzato in men che non si dica!

Pomeriggio
La giornata è proseguita con il seguente programma

Grazie alla mobile app (per Android) della Cloud Conf, ho potuto farmi un’idea sulle tematiche trattate, trovandoli davvero tutti molto interessanti.
Di seguito leggerete un sunto dei 3 talk che ho potuto seguire.
Microservices Architectures on Google Cloud Platform
Lorenzo Ridi, software engineer per Noovle, ci ha raccontato come Google Cloud Platform, con la sua moltitudine di soluzioni, può aiutarci nello sviluppo di architetture più o meno complesse, basate su microservizi in un ambiente completamente gestito.
Ma come mai si è passati dai classici monoliti, ad un’architettura a microservizi?
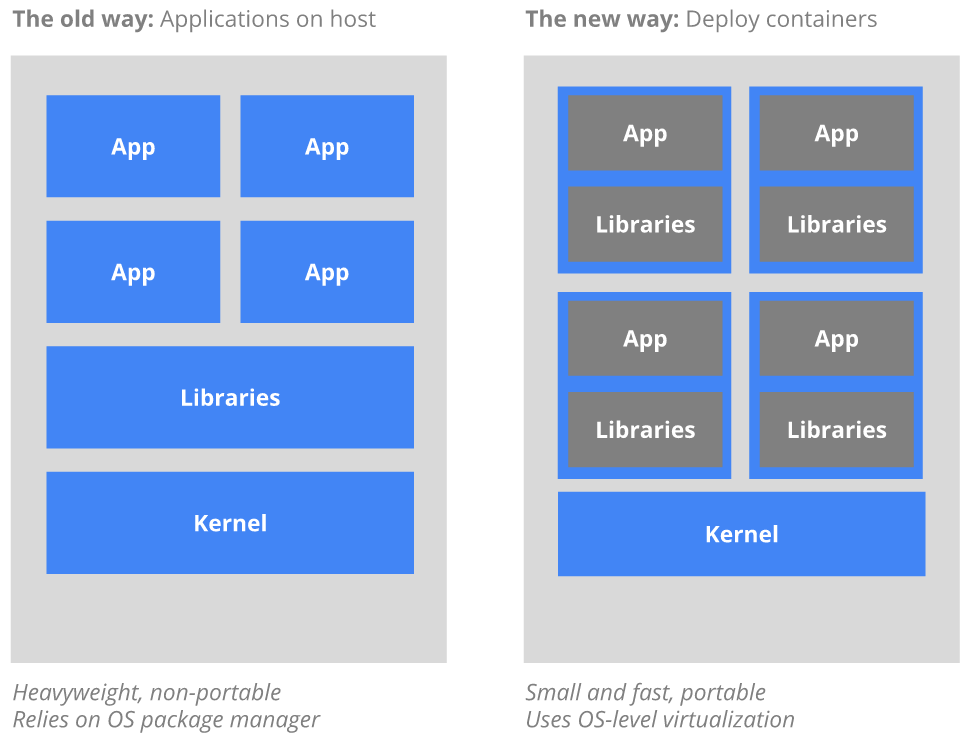
Con il vecchio approccio, l’intera applicazione è deployata in una sola macchina host, e quindi legata da vincoli hardware e software (sistema operativo, file system) della macchina host. Release diverse della stessa applicazione vengono gestite tramite la creazione di macchine virtuali però immutabili, pesanti e non portabili
Il nuovo modo approccio nel distribuire container (Kubernetes, Docker ad esempio) sulla base di virtualizzazione a livello di sistema operativo piuttosto che la virtualizzazione hardware. Questi container sono isolati gli uni dagli altri e verso l’host: hanno file system propri, non possono vedere i processi degli altri, e l’utilizzo delle risorse di calcolo può essere delimitato. Sono più facili da buildare rispetto macchine virtuali, e perché sono disaccoppiati dalla infrastruttura di base e dal file system host, sono portabili attraverso il cloud e le distro del sistema operativo. Rispetto alle macchine virtuali, un container, o anche microservizio, offre vantaggi anche in termini di scalabilità.
Google Cloud Platform offre diverse soluzioni cloud computing:
- Iaas: Infrastructure as a service.
- Paas: Platform as a service.
- Baas: Backend as a service.
- Faas: Function as a service: Google Cloud Functions set di soluzioni serverless, implementate in Node.js.
Relativamente al code & deploy, Google Cloud Function propone soluzioni per:
- Google Cloud Repositories (Github, Bitbucket): esempio di utilizzo del comando gcloud.
- Local file system.
- Cloud console inline editor.
Relativamente al debug & emulation:
- Google Cloud Functions Emulator.
- Debug da Chrome devtools.
Relativamente al logging & monitoring invece, Lorenzo ha introdotto Google Cloud Stackdriver.
Il talk è stato concluso con una piccola demo di un’app che elabora un selfie e restituisce la stessa foto elaborata con simpatici effetti.
Components and Microservices in the front-end world
Matteo Figus, senior software engineer per OpenTable, ha affrontato la tematica dell’approccio a microservizi nel mondo del front-end.
Portando la sua esperienza lavorativa per la piattaforma OpenTable, che gestisce prenotazioni in ristoranti registrati in tutto il mondo, ha spiegato come ogni pagina del sito, ogni componente può essere vista e quindi trattata come microservizio.
La home page, la barra di ricerca, il footer…ogni elemento di per se è gestito come web app, in quanto ha una su back-end e complessità.
Matteo ci ha spiegato che attualmente la piattaforma è formata da più di 18 microsite, e più di 100 microservizi. Lavorano più di 20 team che eseguono centinaia di deploy settimanali.
In che modo è possibile lavorare gestendo componenti di front-end come microservizi?
La risposta, perlomeno dall’esperienza di Matteo, è OpenComponents, un framework opensource che appunto facilita lo sviluppo e deploy di componenti front-end.
Con una breve demo, ci ha fatto vedere come installare la libreria (npm install opencomponent) e come con un semplice comando
oc init <nome componente>
la libreria ti crea la struttura view-model di un nuovo componente.
Personalmente uno dei talk più interessanti, mai avrei pensato di vedere un sito web, una piattaforma come un insieme di microservizi!
Qui le slide dell’intervento.
Handle insane traffic with Google Cloud Platform
Marco Tranquillin, cloud program manager per Google, ha spiegato come gestire l’enorme mole di dati reperibile dal cloud tramite la suite di prodotti Google Cloud Platform.
Nei primi minuti del talk, Marco ha fatto un excursus sull’organizzazione del Google Cloud Network, ricordandoci che è la prima azienda ad avere installato dorsali oceaniche proprietarie, e che quindi tutto il traffico di dati è sicuro appunto perché i dati viaggiano nelle loro dorsali.
Ci ha mostrato i data center attivi, e quelli che sono in fase di attivazione.
Tornando a Google Cloud Platform, Marco ha quindi iniziato a parlarci di alcuni servizi offerti in termini di:
- Data analytics
- Application development
- Infrastructure e operations
Ponendo il focus sull’analisi del dato, Google ha sviluppato sue soluzioni:
- Cloud storage: BigQuery
- Logging
- Google Cloud SQL
partendo da soluzioni note (Kafka, Cassandra, MongoDb, Hadoop etc.).

Dopo averci ricordato l’appuntamento di Google Next classico talk annuale dove si presentano le novità, Marco è passato alla sua demo, che personalmente ho trovato la più sorprendente della giornata.
Ciò che ha voluto mostrarci è la potenza di calcolo della suite di prodotti Google Cloud platform, simulando uno scenario IoT di raccolta dati di sensori (virtuali ovviamente) distribuiti in tutto il mondo. I sensori inviano dati alla piattaforma che li gestisce in 2 database separati. Di questi dati poi, si possono effettuare query e report.
Ciò che ho trovato interessante è stata la semplicità delle operazioni eseguite da Marco durante la demo.
Sempre e solo comandi in pagine web della piattaforma Google Cloud.
Ad esempio, il pannello di controllo dal quale ha avviato le 6 macchine virtuali, ognuna delle quali avviava un semplice programmino Java per la generazione di dati dei nostri sensori. A tal proposito, ci ha mostrato come eseguire la shell di ognuna delle 6 macchine virtuali per comandarle.
Di grande effetto è stato notare la rapidità con il quale il sistema ha risposto ad una query eseguita su una delle tabelle contenenti i dati generati durante la demo. Da una tabella di dimensione relativamente grande (circa 191 GB), il sistema ha impiegato solamente 4 secondi per restituire i dati. Dati che poi Marco ha dato in pasto a Google Data Studio per presentarli in un report.
Insomma, Google Cloud Platform offre un ecosistema di sistemi, come dice Marco, in continua crescita. Alcuni di questi sono gratuiti entro certi limiti di dati (ad esempio Google App Engine), altri a pagamento fin da subito. Quello che ci rimane da fare è provare, dato che se si possiede un account Gmail, si ha diritto ad un voucher di 300$ di durata annuale.
Chiusura lavori
Concluso l’ultima sessione di talk, erano già le 17 circa…ora di andare!
Durante il key-note di chiusura di Walter Dal Mut, uno tra gli organizzatori della conferenza, abbiamo smontato lo stand e fatto ritorno alle nostre case, stanchi ma allo stesso tempo carichi e soddisfatti della giornata.
Di questa edizione della Cloud Conf porto a casa la consapevolezza che nel mondo del software è sempre più forte la spinta verso soluzioni orientate ai microservizi, in sfavore dei tanto cari ma quanto sempre più obsoleti monoliti.
Stiamo vivendo in pieno la Quarta rivoluzione industriale, dopotutto.
Alla prossima edizione!