FizzBuzz design e refactoring: un trinomio vincente.
Uno dei talk tecnici dell’Agile Venture di Firenze ha riguardato il kata del FizzBuzz.
Per quei pochi che non conoscono l’argomento, l’obiettivo è stampare una lista di numeri, la parola Fizz per tutti quelli divisibili per 3, Buzz per i divisibili per 5 e FizzBuzz per i divisibili sia per 3 che per 5.
Massimo Iacolare non vuole dedicare l’intervento What FizzBuzz can teach us about design alla risoluzione dell’esercizio, di per sé molto semplice, bensì degli insegnamenti che potremmo trarre dal design qualora sopraggiungesse una nuova feature da implementare, ovviamente applicando TDD. Nessuna lezione su architetture software, ma micro osservazioni al codice e refactoring,
Osservare bene il codice è importante per fare refactoring e poi apportare la modifica; meglio ancora se lo si fa partendo da del codice scritto bene. Inoltre fare Kata di programmazione è un ottimo modo per migliorare la propria tecnica.
FizzBuzz design e refactoring: si può fare.
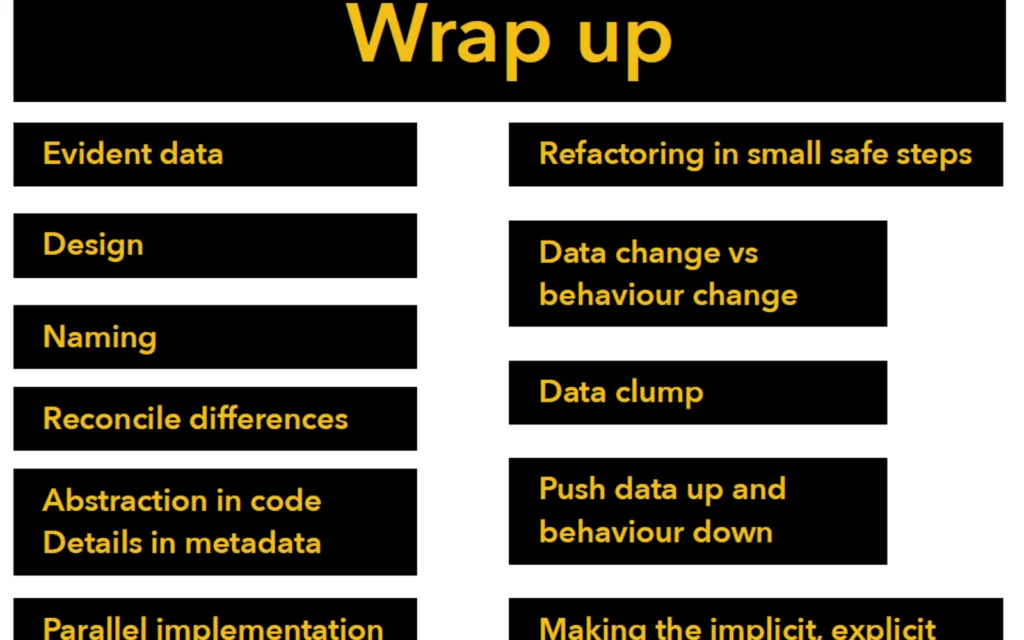
Nuova feature e impatto sul codice
Analizzando la codebase (implementazione e casi di test), Massimo fa notare che qualcosina è migliorabile. Introduciamo la feature ora, e cioè stampare Bang per tutti i numeri divisibili per 7. Ovviamente la feature non deve rompere l’attuale comportamento, per cui vanno tenuti in considerazione anche i seguenti casi:
- 3,7 -> FizzBang
- 5&7 -> BuzzBang
- 3&5&7 -> FizzBuzzBang
Gestire un ulteriore divisore ha un impatto sia sul codice che nei test, e si passerebbe da 3 ramificazioni, o meglio branch (istruzione if nel codice), a 7. Verrebbe da pensare di aggiungere degli if per implementare la richiesta, ma cosa succederebbe se si decidesse di aggiungere un ulteriore divisore, ad esempio il numero 11? Si avrebbero ben 19 ramificazioni. Decisamente troppe.
Come agire quindi? Modifichiamo in base ai dati (data change) o al comportamento (behaviour change)?
E’ meglio fare prima refactor per preparare il campo alla nostra modifica, agendo a piccoli passi lasciandosi guidare dai test piuttosto che implementare prima la richiesta e poi eseguire il refactor.
E già che ci siamo, proviamo a implementare la modifica con una sola riga di codice, magari eliminando tutti i branch.



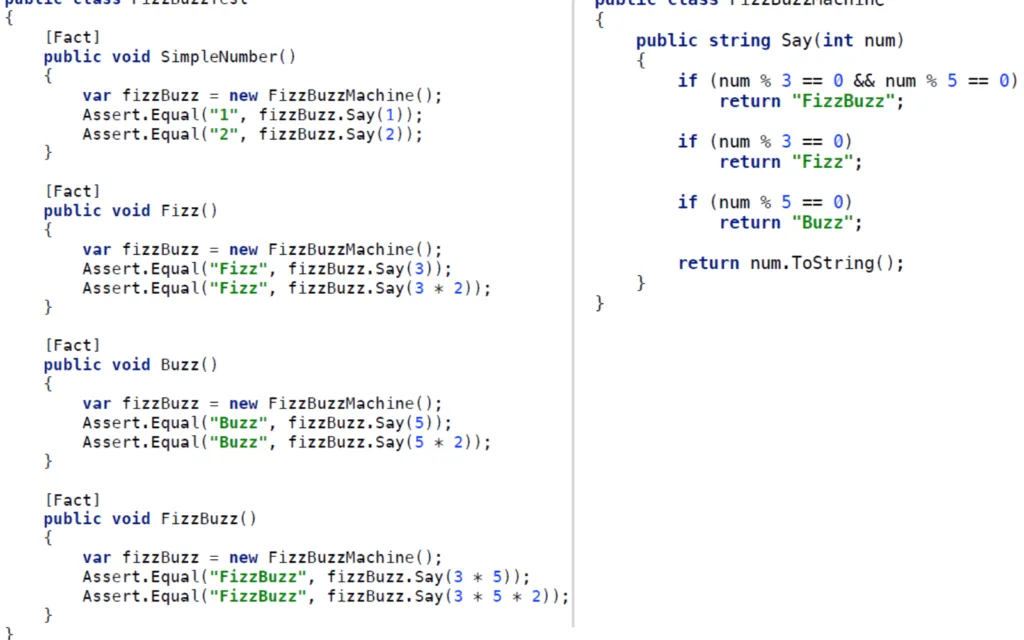
Refactoring del codice esistente
Da dove iniziare? Si chiede Massimo. Non c’è una risposta precisa, ma analizzando il codice un primo step potrebbe essere quello di rivelare l’intento dei dati evidenziando la loro relazione.
Evident Data, per riassumerlo in due parole. Nel caso specifico, isoliamo Fizz e Buzz dopodiché introduciamo una variabile che viene composta dalle parole in base al dato.
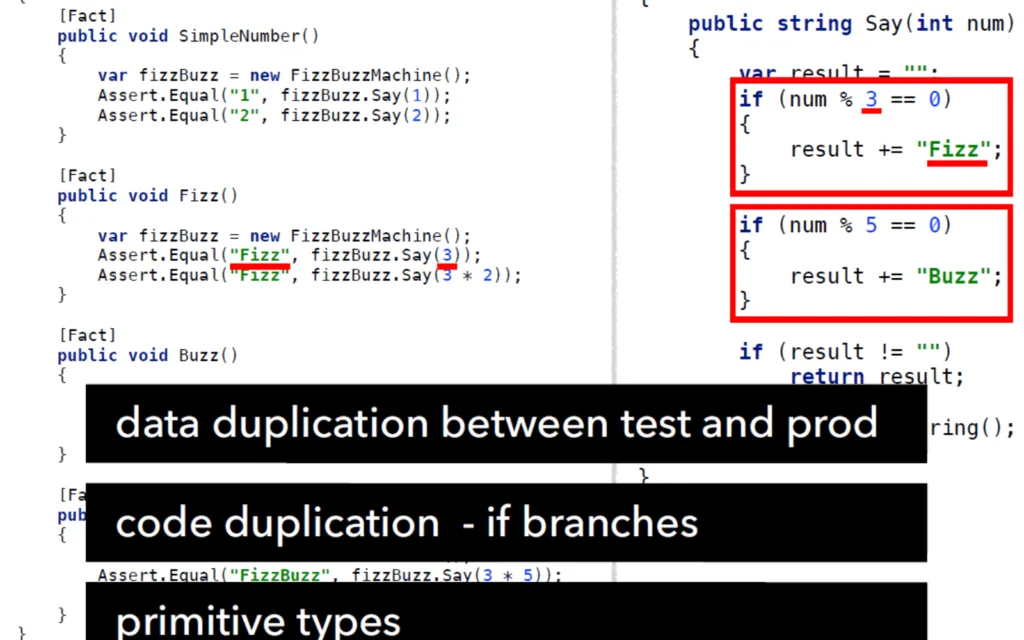
Il codice è migliorato, ma ci sono altri problemi:
- duplicazione di dati tra codice di test e produzione
- duplicazione di branch per il controllo del divisore
- uso di tipi primitivi
Potremmo introdurre un metodo che riduca i branch, e dargli un nome significativo come IsDivisible.
Per eliminare del tutto la duplicazione di codice, si potrebbe poi introdurre un parametro per il divisore ed uno per la parola. Un numero ed una stringa, correlati tra loro. Perché non creare un oggetto, in questo caso una tupla. Ecco come sbarazzarci di uno dei tanti code smell, il Data Clump.
Introducendo un metodo e variabili, il codice via via sta migliorando. E’ importante dare nomi che siano chiari ed evocativi, e a tal proposito Massimo consiglia la lettura di una serie di articoli Naming is a process.
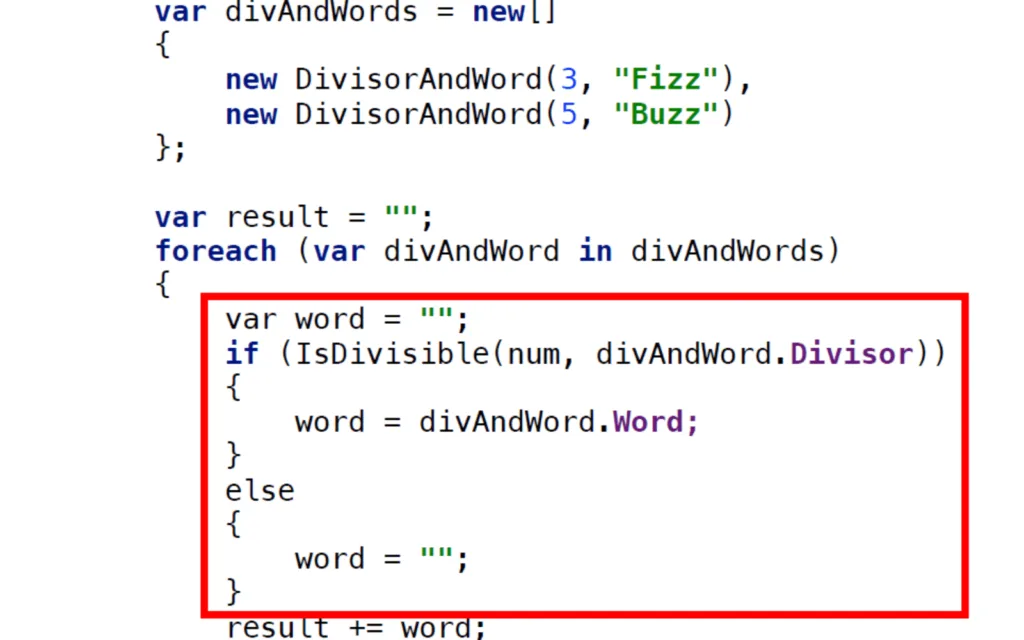
Tornando al refactoring, il codice potrebbe essere ulteriormente migliorato per eliminare le chiamate multiple al metodo IsDivisible. Perciò introduciamo un array da iterare per valutare.
Ancora si fa uso dei tipi primitivi, introduciamo la classe DivisorAndWord contenente appunto l’intero e la stringa. Eseguiamo un ulteriore ottimizzazione al codice per eliminare rami else impliciti. Si arriva ad un punto in cui il codice è così strutturato:
- inizializzazione dell’array
- iterazione dell’array con logica per calcolo della parola
returndella parola calcolata
Introducendo un metodo EvaluateAndGetWordOrEmpty potremmo estrarre la logica e avere un codice ancora più pulito e descrittivo, inoltre la parte di inizializzazione dei dati si potrebbe anzi dovrebbe portare in alto e staccarla dal comportamento. Push data up and behaviour down.
Perché non fare refactoring anche del codice dei test? Adattiamo il nuovo codice ai test e notiamo che alcuni sono duplicati perciò posso essere rimossi.
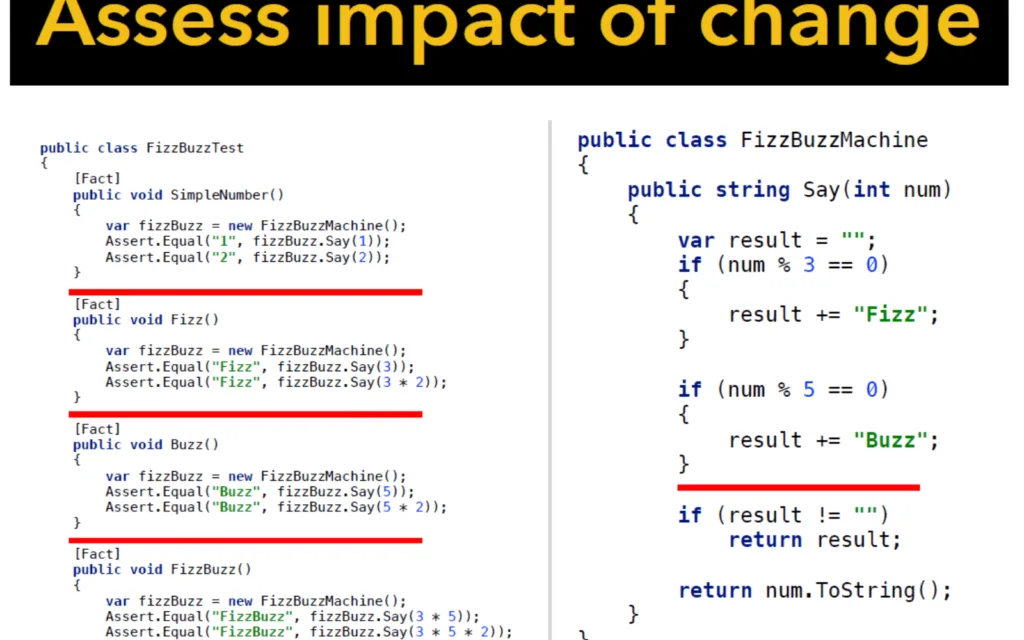



Implementiamo la modifica richiesta
Ricordate la sfida iniziale? Implementare la modifica con una sola riga di codice. Ebbene, aggiungendo una nuova istanza DivisorAndWord(7, "Bang") il gioco è fatto.
Ma non il lavoro, dato che si potrebbero fare ulteriori modifiche ai nomi dei metodi e variabili e quant’altro, ma il tempo a disposizione di Massimo è terminato purtroppo.
Come anticipato ad inizio sessione, seppur semplice questo Kata ci porta o meglio riporta alla luce molti insegnamenti.
Un sincero grazie Massimo, hai condotto un talk molto istruttivo.
Nel paragrafo Riferimenti potete trovare il link alle slide della presentazione e al codice su github.