
Conosciamo GitLab pipeline come strumento di Continuous Integration
Un classico problema per chi sviluppa software è l’integrazione di codice nuovo all’interno di un progetto consolidato.
Può sembrare un’operazione banale, e spesso mi è capitato di sentire frasi del tipo “Basta il buon senso” oppure “Con un po’ di attenzione certe cose non succedono” ma chiunque, nella sua breve o lunga carriera lavorativa, ricorda almeno un episodio in cui parecchio tempo è andato perduto a causa di una piccola distrazione tra le nuove righe scritte da qualcuno di fretta.
L’obiettivo è avere uno strumento che ci permetta di evitare tutto ciò, in modo automatico e che sia facile da manutenere: Gitlab pipeline.
In questo articolo vi spiegherò quanto ho imparato di questo strumento, la sua architettura e le caratteristiche principali, entrando nel merito del formato YAML che permette di implementare una pipeline Gitlab
Gitlab pipeline – Prerequisiti
I prerequisiti per poter sfruttare le pipeline sono:
- Il progetto deve usare Git (1) come sistema di versionamento.
- Il progetto deve essere in un linguaggio supportato dalle pipeline (altrimenti potrete comunque utilizzare Gitlab come repository ma dovrete fare a meno di questa funzionalità.
- Avere un’organizzazione accurata e sensata dei rami di sviluppo (ad esempio adottando il workflow Gitflow) in modo da poter isolare i rami da cui estrarre le versioni da rilasciare, in genere il ramo master, e i rami dove convergono gli sviluppi correnti, ad esempio il ramo develop o rami con nomi standard, creati per raggruppare sviluppi importanti con molte feature.
- Avere dei test sul codice, senza test potremmo solamente garantire che il codice venga compilato e nulla più.
Gitflow workflow
Avendo un ambiente con le caratteristiche sopra citate dobbiamo capire dove sono i punti critici in cui potrebbero verificarsi i problemi e cosa fare per avere la garanzia che il nostro codice sia come lo vogliamo.
Prendendo come esempio il celebre grafico di Gitflow (2) riportato nell’immagine seguente, possiamo elencare i vari scenari.
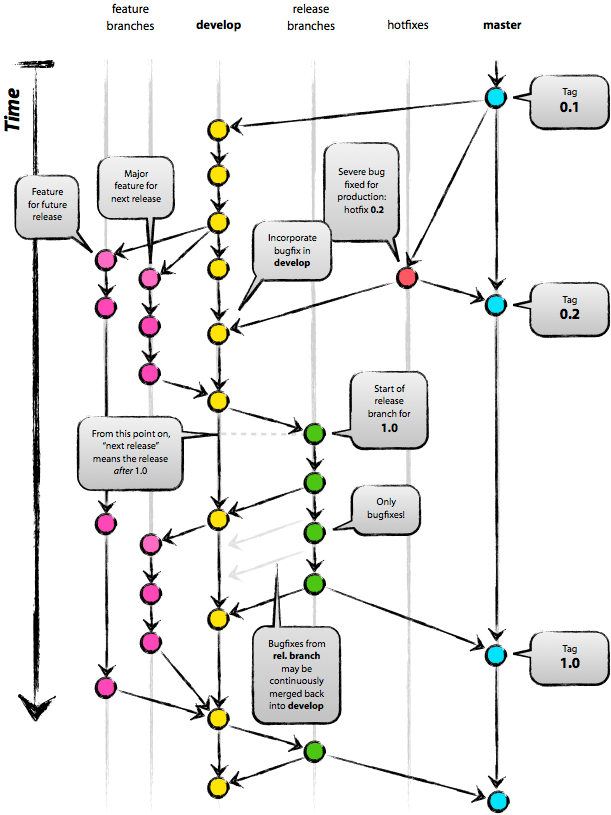
In caso di risorse illimitate, sia in termini economici che di tempo, potremmo far sì che la pipeline venga eseguita ad ogni commit, validando l’intero progetto in ogni singolo commit. Sconsiglio comunque questo approccio in quanto non si ha mai (perlomeno nel 99% dei progetti) l’esigenza di validare ogni singolo commit e dunque avremmo uno spreco di risorse, soprattutto in presenza di team composti da diverse persone.
Nel caso più comune avremo bisogno di avere una garanzia di correttezza quantomeno sui rami, o branch in gergo: master, develop e release, ovvero i punti in cui i vari sviluppi convergono e dunque quando i possibili errori di integrazione inizierebbero ad emergere. In questi punti, in presenza di test scritti bene, in caso di errori la pipeline dovrebbe fallire e dunque evitarci di dover risalire i commit per capire quale di essi ha dato errore.
Ora che sappiamo dove e quando vorremmo eseguire le nostre pipeline non ci resta che esaminarle.
Anatomia di una pipeline GitLab
La pipeline è definita all’interno di un file chiamato gitlab-ci.yml che definisce i vari step e ogni linguaggio ha le sue operazioni standard.
Nel file troviamo le seguenti componenti:
- Stages dove fissiamo gli step costitutivi della nostra pipeline.
- Variables dove definiamo delle variabili comuni ad ogni step (stage).
- Before_script: qui vengono definite delle operazioni preliminari di un job.
- Una serie di nomi variabili (non riservati) con molte property, tra le quali:
- Stage: che raggruppa i vari step e definisce anche quando verranno eseguiti.
- Script: il comando da eseguire.
- Only: dove si definiscono le restrizioni di ramo. Qui possiamo scegliere se eseguire alcuni step (ad esempio per il deploy) solo per alcuni rami speciali.
Per quanto ci riguarda le variazioni possono essere tante, ogni progetto ha i propri vincoli e preferenze e dunque la pipeline rispecchierà tali esigenze.
Per ulteriori approfondimenti sulla configurazione di una pipeline rimando alla documentazione ufficiale (3). Qualora voleste saperne di più sui file .yml, consiglio di visitare la pagina con esempi per ogni linguaggio supportato (4).
Un esempio di job definito in gitlab-ci.yml
L’immagine seguente è uno screenshot di un job:
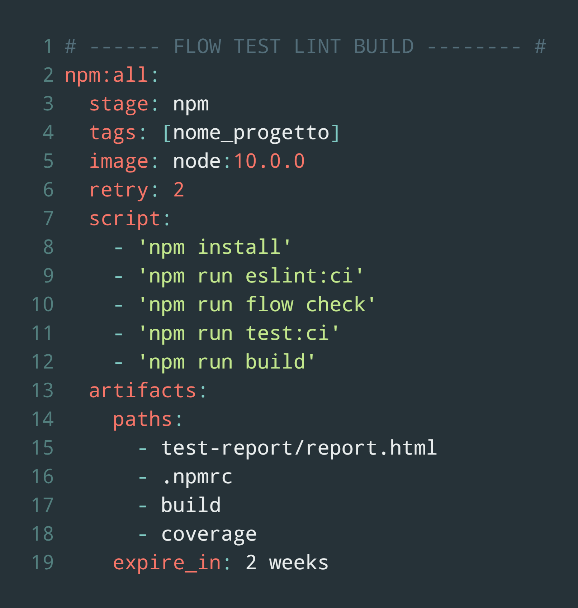
Analizziamo il codice di questo job:
- Definiamo uno step dove definiamo che lo stage sarà npm.
- In tags scriviamo i tag che ci servono, nel nostro caso il nome del progetto.
- In image definiamo l’immagine Docker in cui verrà eseguito questo job.
- Con retry definiamo il numero di volte che questo step verrà rieseguito.
- In script troviamo il cuore dell’operazione ovvero i comandi da eseguire. Nel nostro caso installiamo le librerie ed eseguiamo i test di eslint, flow, i test d’integrazione e proviamo ad eseguire la build.
- In artifact definiamo dove salvare tutti i dati utili prodotti dai comandi e per quanto saranno validi (presenti nello spazio dedicato).