
Data Warehouse: Amazon Redshift e Google BigQuery
Il Data Warehouse su cloud è diventato una componente fondamentale per le organizzazioni moderne che cercano di estrarre valore dai loro dati. Con l’aumento esponenziale dei volumi di dati, le soluzioni tradizionali di Data Warehouse on-premise non sono più sufficienti per soddisfare le esigenze di scalabilità, flessibilità e costi delle imprese. In questo contesto, soluzioni su cloud come Amazon Redshift e Google BigQuery offrono potenti alternative.
Questo articolo fornisce un confronto tra queste due piattaforme, esaminando le loro caratteristiche, vantaggi, costi e un esempio di funzionamento di entrambi i servizi. L’obiettivo è aiutare a comprendere quale soluzione si adatta meglio alle esigenze specifiche di ognuno.
Cos’è un Data Warehouse su Cloud?
I Data Warehouse su cloud sono piattaforme di archiviazione dati progettate per facilitare la raccolta, la gestione e l’analisi di grandi quantità di dati provenienti da varie fonti e si differenziano per diversi aspetti dai database tradizionali:
- Architettura: i Data Warehouse (nel seguito DW) sono ottimizzati per operazioni Online Analytical Processing (OLAP), supportano l’aggregazione, l’analisi dei dati e le query complesse. Utilizzano un’architettura a colonne che consente un’efficiente compressione dei dati e velocizza le operazioni di lettura.
I database tradizionali (nel seguito DB) invece sono generalmente ottimizzati per operazioni Online Transaction Processing (OLTP), gestiscono un alto volume di transazioni brevi e frequenti. Utilizzano un’architettura a righe che è più efficiente per operazioni di scrittura e aggiornamento frequenti. - Scalabilità: anche in questo caso i DW sono progettati per scalare orizzontalmente, consentendo l’aggiunta di risorse in base al volume di dati e alla complessità delle query senza degrado delle prestazioni, mentre i DB scalano tipicamente verticalmente, aumentando le risorse di un singolo server per gestire carichi di lavoro crescenti, ma con limitazioni rispetto alla scalabilità orizzontale.
- Gestione dei dati: i DW sono ideali per integrare e analizzare dati provenienti da varie fonti (ETL: Extract, Transform, Load), consentendo una visione unificata e completa dei dati aziendali, a differenza dei DB che sono progettati principalmente per gestire dati operativi in tempo reale, adatti per applicazioni transazionali dove l’integrità dei dati e la velocità delle transazioni sono critiche.
- Costo: per la gestione dei costi, a differenza dei DB tradizionali in cui il costo può essere legato alla capacità delle risorse allocate, i DW spesso adottano un modello di pricing basato sul consumo, permettendo di pagare solo per le risorse effettivamente utilizzate.
Di seguito andremo a vedere quali sono le principali soluzioni di Data Warehouse offerti da Amazon e Google.
Amazon Redshift
Amazon Redshift è il servizio di Data Warehouse e analisi dati offerto da Amazon Web Services (AWS).
Questo servizio utilizza un’architettura distribuita e parallela che consente di scalare orizzontalmente il cluster in base alle esigenze del carico di lavoro. Ciò significa che è possibile aumentare o diminuire facilmente le risorse di calcolo e di archiviazione per adattarsi alle esigenze del carico di lavoro.
Amazon Redshift si integra perfettamente con l’ecosistema AWS, consentendo l’acquisizione, la preparazione e l’analisi dei dati in un ambiente cloud integrato. È possibile utilizzare servizi come Amazon S3, AWS Glue e AWS IAM per semplificare il processo di gestione dei dati.
Costi
I costi di Amazon Redshift dipendono principalmente da due fattori principali:
- Dimensione del Cluster: viene addebitato un costo orario in base alle dimensioni del cluster Redshift utilizzato. Questo costo dipende dal numero di nodi di calcolo e di archiviazione configurati per il cluster.
- Utilizzo delle Risorse: viene addebitato anche un costo per l’utilizzo effettivo delle risorse, come le query eseguite e lo storage dei dati. Le query più complesse o che scansionano grandi volumi di dati possono comportare costi più elevati.
Quando utilizzare Amazon Redshift
Amazon Redshift è particolarmente vantaggioso per chi utilizza già l’ecosistema AWS per altri servizi e applicazioni, semplificando l’acquisizione, la preparazione e l’analisi dei dati.
Google BigQuery
A differenza degli altri servizi Google BigQuery è completamente serverless, il che significa che non richiede la gestione dell’infrastruttura sottostante. Google si occupa automaticamente di tutte le attività di provisioning delle risorse, garantendo prestazioni elevate e una scalabilità automatica.
Il servizio si integra inoltre perfettamente con altri servizi di Google Cloud Platform, consentendo l’acquisizione, la preparazione e l’analisi dei dati in un ambiente integrato. È possibile utilizzare strumenti come Looker Studio (ex Google Data Studio) e Google Cloud Storage per completare il processo di analisi dati.
BigQuery offre anche funzionalità integrate di machine learning (BigQuery ML) che consentono agli utenti di eseguire modelli di machine learning direttamente sui dati memorizzati al suo interno, senza dover trasferire i dati altrove.
Costi
I costi di Google BigQuery dipendono dai costi di calcolo e dai costi di archiviazione. Per i primi il modello prevede due modalità:
- Pricing on-demand (per TiB): In questo modello, paghi in base ai byte elaborati da ciascuna query. I primi 1 TiB di dati processati al mese sono gratuiti.
- Pricing a capacità (per slot-ora): In questo modello, il costo dipende dalla capacità di calcolo utilizzata per eseguire le query, misurata in slot (CPU virtuali) nel tempo. È possibile utilizzare l’autoscaler di BigQuery o acquistare slot dedicati a un prezzo inferiore per garantire capacità costante per i tuoi carichi di lavoro.
Per i costi di archiviazione invece viene addebitato lo spazio dei dati caricati.
Quando utilizzare Google BigQuery
Google BigQuery è particolarmente vantaggioso se si preferisce evitare la gestione dell’infrastruttura sottostante, eliminando la necessità di provisioning, monitoraggio e gestione dei cluster o per chi utilizza già Google Cloud Platform per altri servizi e applicazioni. Inoltre, grazie al modello di pricing basato sul consumo, BigQuery è particolarmente adatto per carichi di lavoro con picchi di utilizzo variabili, consentendo di pagare solo per le risorse effettivamente utilizzate.
Un esempio pratico
Ora che sappiamo cosa è un Data Warehouse, vediamo come si utilizza negli ambienti offerti da Google (Google Cloud Platform) e Amazon (Amazon Web Services).
Nel seguito verranno descritte le procedure per eseguire l’importazione del contenuto di un file in formato JSON opportunamente popolato di dati in una tabella di un database. Nello specifico i file utilizzati contengono le singole frasi estratte da un libro con l’indicazione del titolo, della riga in cui sono posizionate, il numero di parole e caratteri da cui sono composte.
Cominciamo con BigQuery di Google Cloud.
Google BigQuery
Una volta eseguito l’accesso accediamo alla Gestione risorse per creare un nuovo progetto:
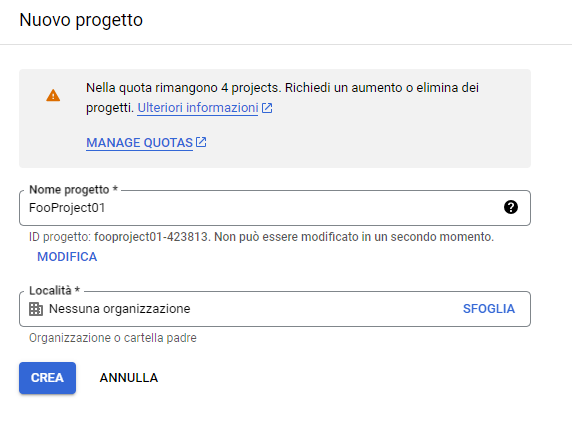
Creato il progetto accediamo alla sua dashboard e selezioniamo “Storage”.
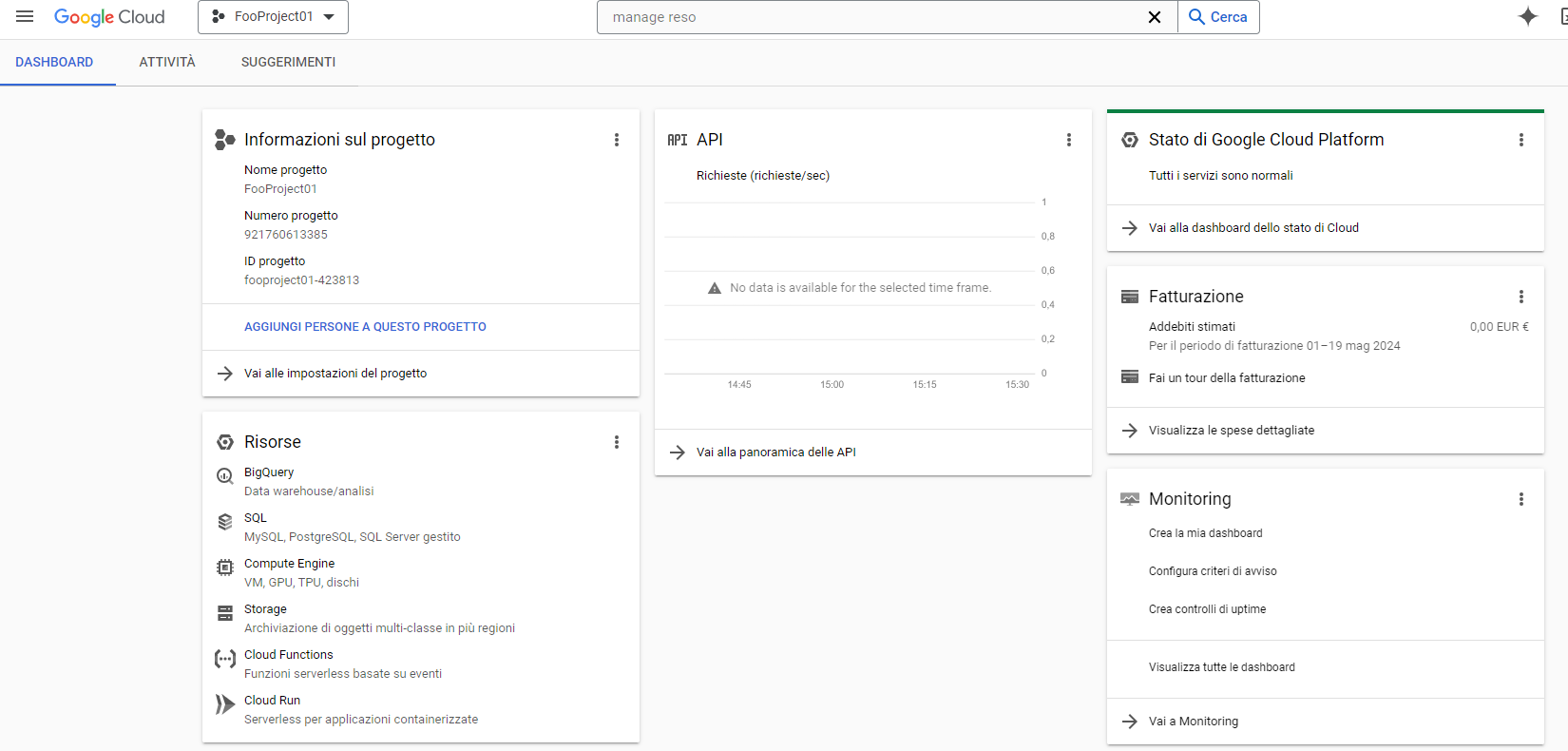
Per poter rendere disponibili i dati da importare nel database bisogna creare un bucket su cui caricare i file destinati all’importazione. Selezioniamo quindi “Crea”:
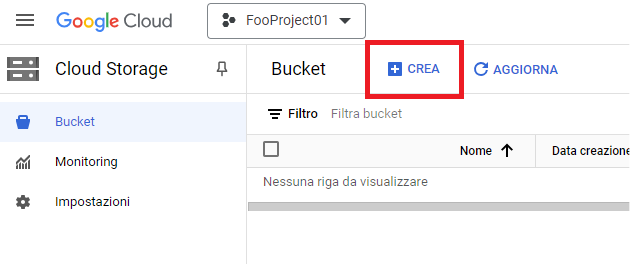
Nella schermata successiva impostiamo il nome del bucket e la regione, lasciando tutti gli altri parametri ai valori predefiniti:
Quando proposto, raccomandiamo di prevenire l’accesso pubblico al bucket:

Possiamo ora caricare i file da cui desideriamo importare i dati:
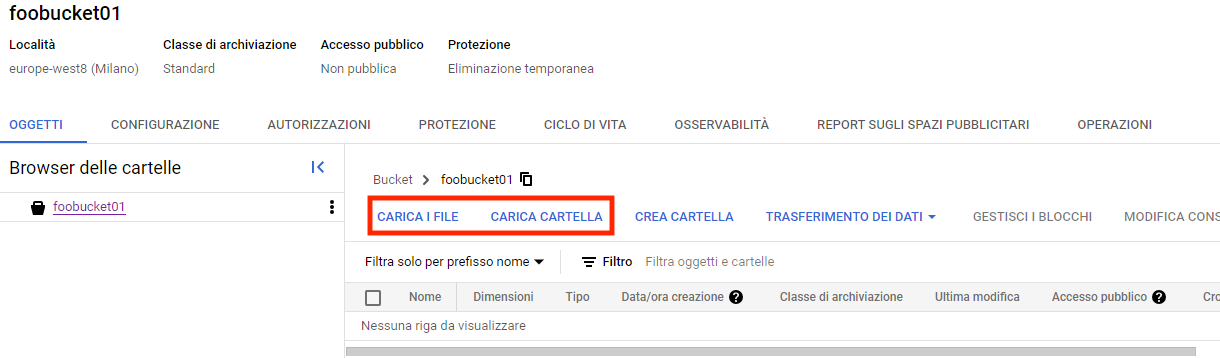

Ora che i file sono disponibili ai servizi in cloud, passiamo alla creazione del database.
Torniamo alla dashboard del progetto e selezioniamo “BigQuery”:
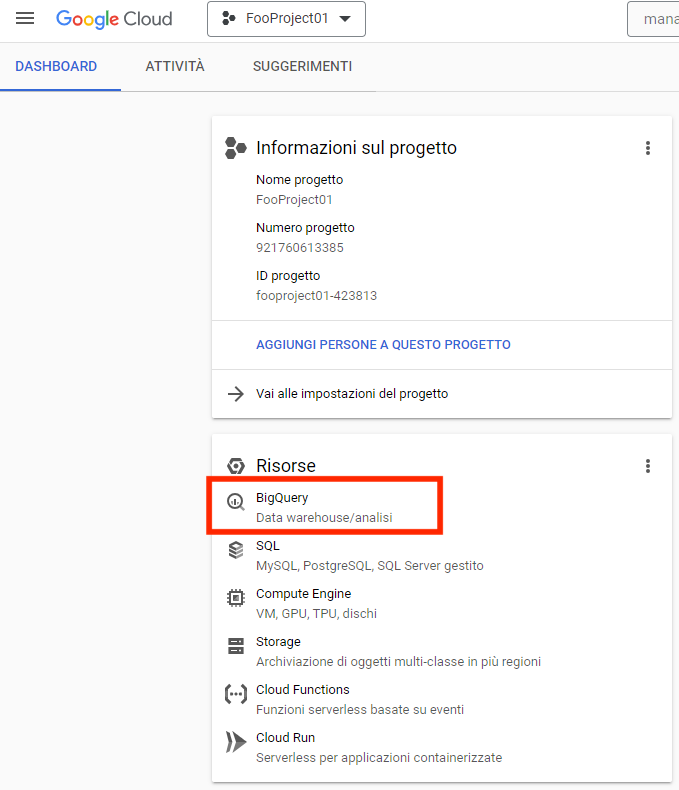
Quando proposto abilitiamo le BigQuery API:

Terminata l’abilitazione si avrà accesso a BigQuery Studio, in cui creeremo il nostro primo dataset:
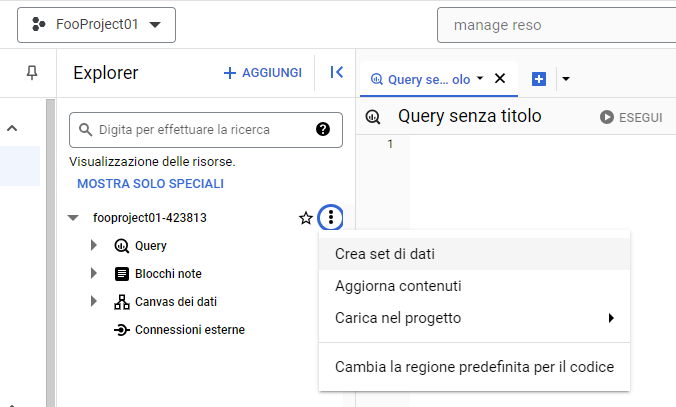
Attribuiamo il nome che preferiamo e definiamo la stessa regione del bucket per consentire a BigQuery di accedere ai file caricati sullo stesso:
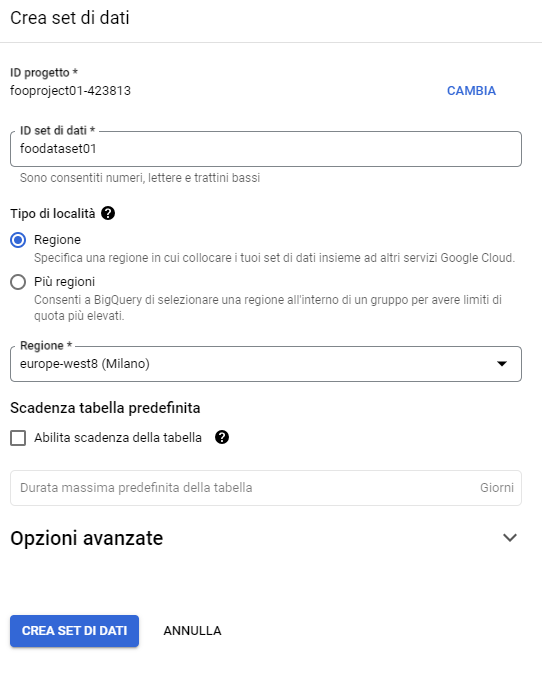
Quindi dal set di dati avviamo la creazione della nostra prima tabella:
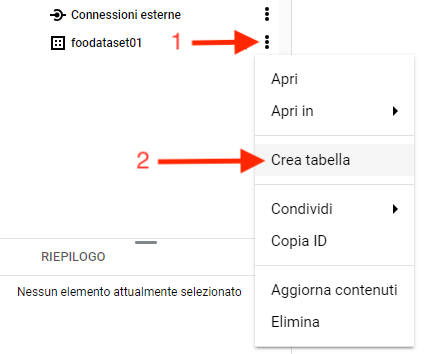
Nella procedura di creazione tabella sarà sufficiente specificare progetto, dataset, nome tabella e la definizione dei campi della tabella, lasciando al valore predefinito tutti gli altri valori.
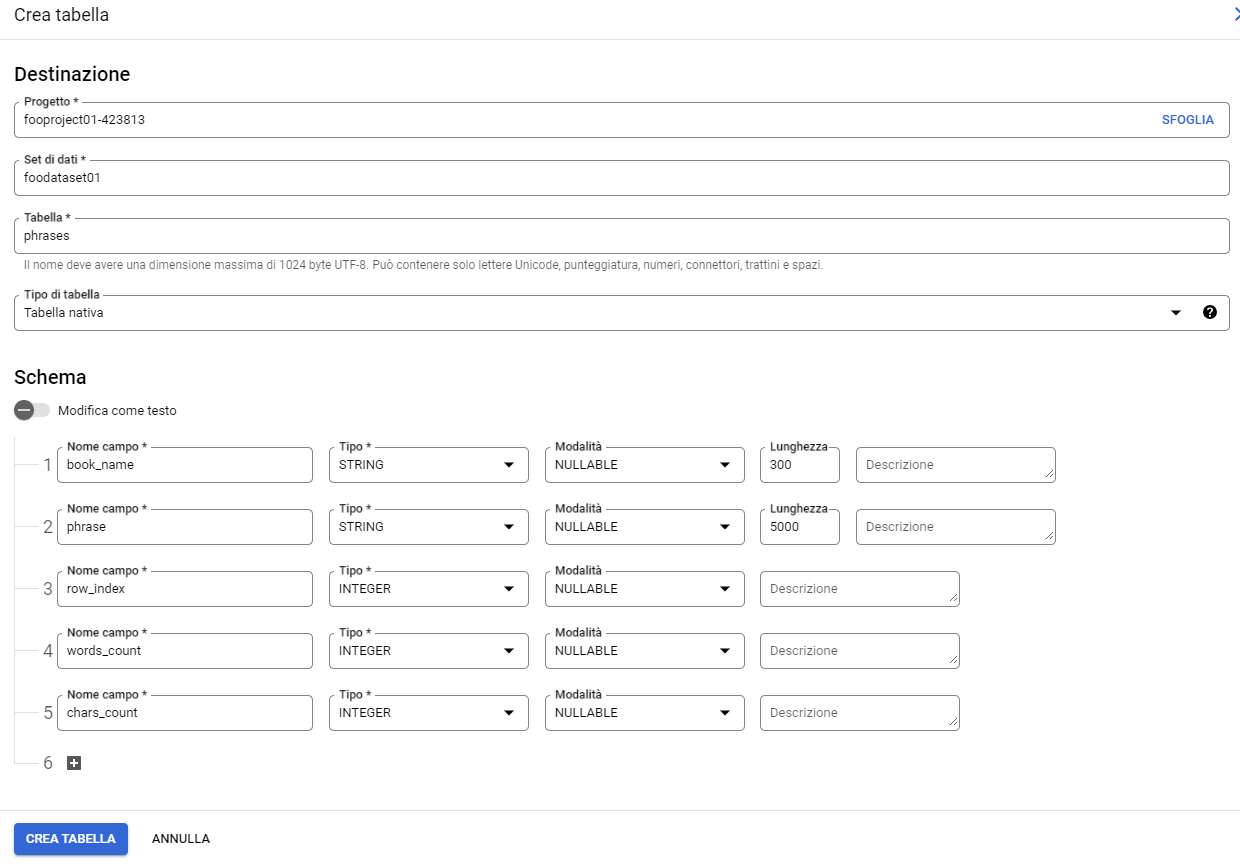
Ora che abbiamo una tabella possiamo avviare il trasferimento dei dati residenti sul bucket.
Dal menu “Analisi” selezioniamo “Trasferimenti”:
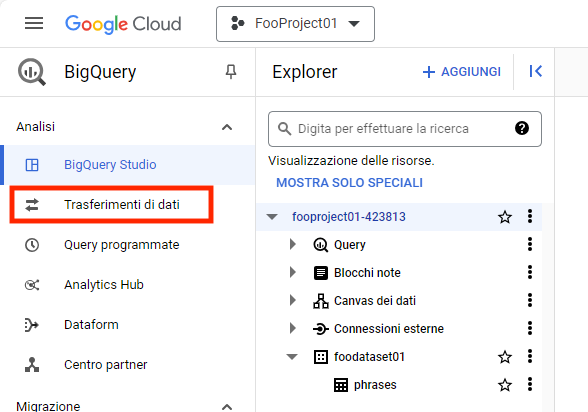
E quindi “Crea trasferimento”. Quando proposto abilitiamo le API necessarie:
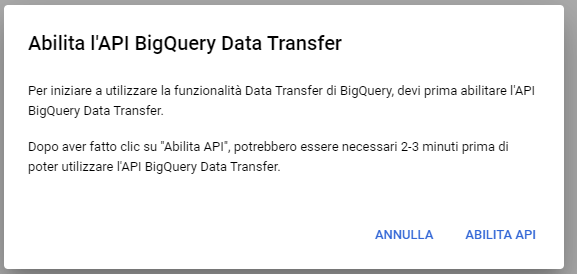
E definiamo i parametri di importazione:
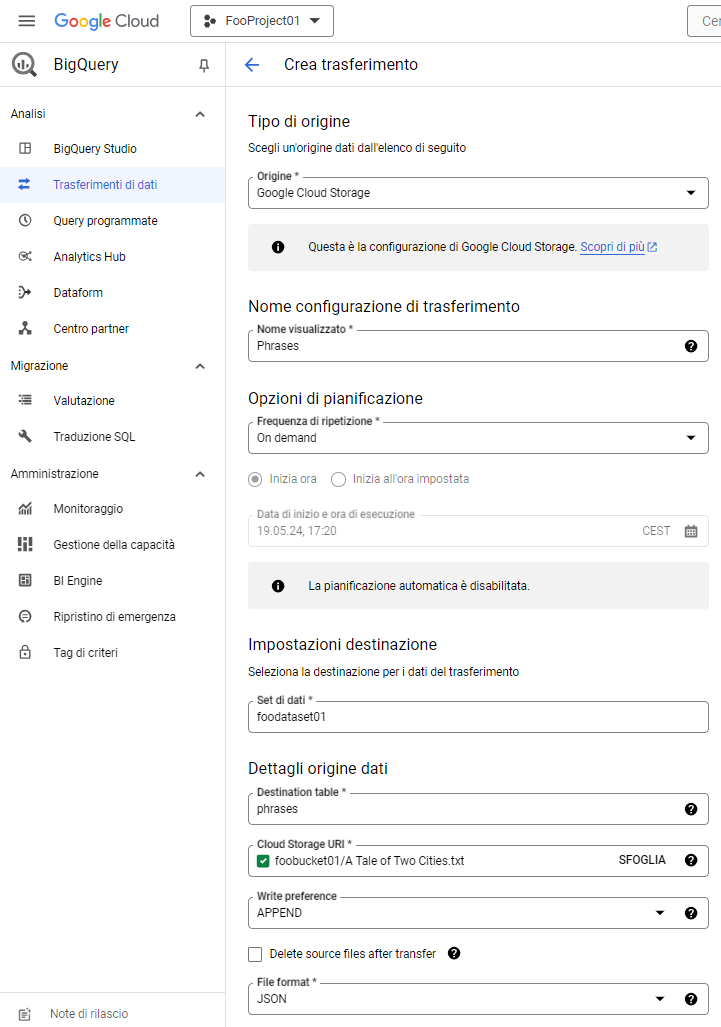
Prima di salvare il job di trasferimento è anche possibile abilitare la notifica via email:

Salviamo il job e lo eseguiamo:

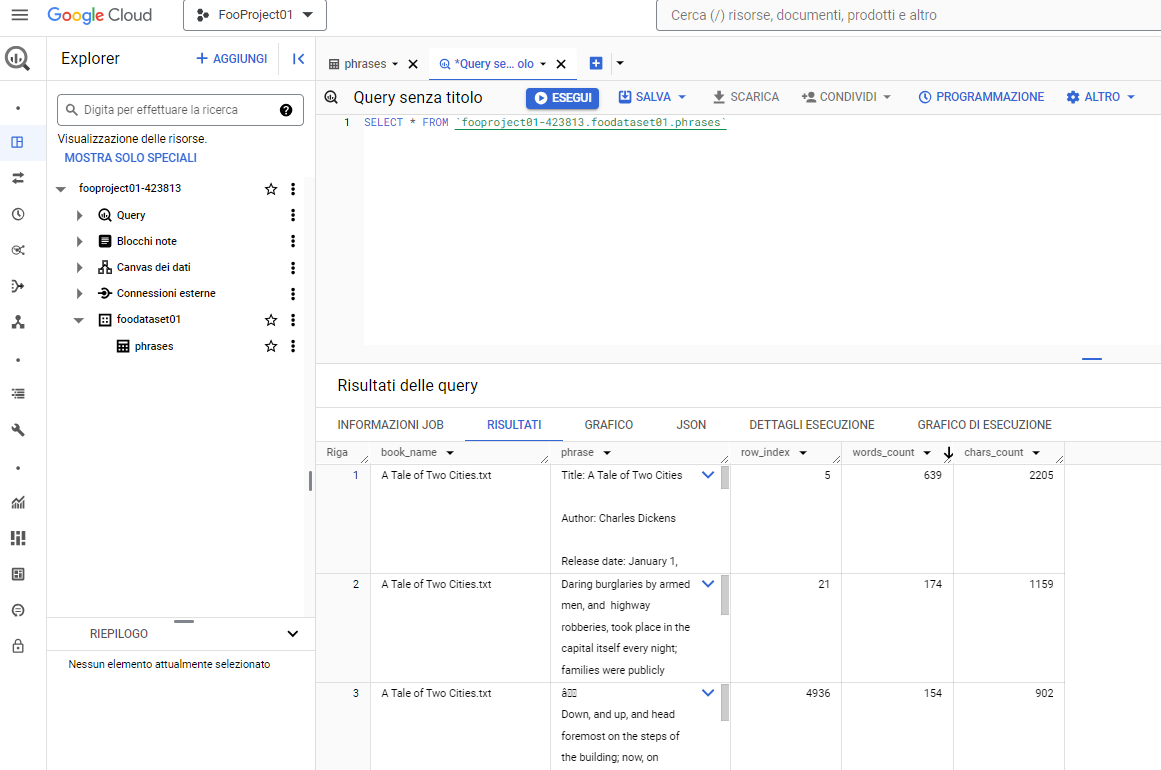
Una volta terminato il trasferimento sarà possibile verificare il contenuto della tabella in BigQuery Studio eseguendo una query:
Amazon Redshift
Di seguito vi mostreremo il procedimento, molto simile al precedente, utilizzando Amazon Redshift (Amazon Web Services).
Cominciamo con la creazione del bucket su cui caricare i file di cui desideriamo importare i dati.
Eseguiamo l’accesso alla console e dall’elenco dei servizi selezioniamo “S3”:
Creiamo il bucket nella regione che desideriamo utilizzare:
Sarà sufficiente definire il nome lasciando tutte le altre impostazioni al valore predefinito:
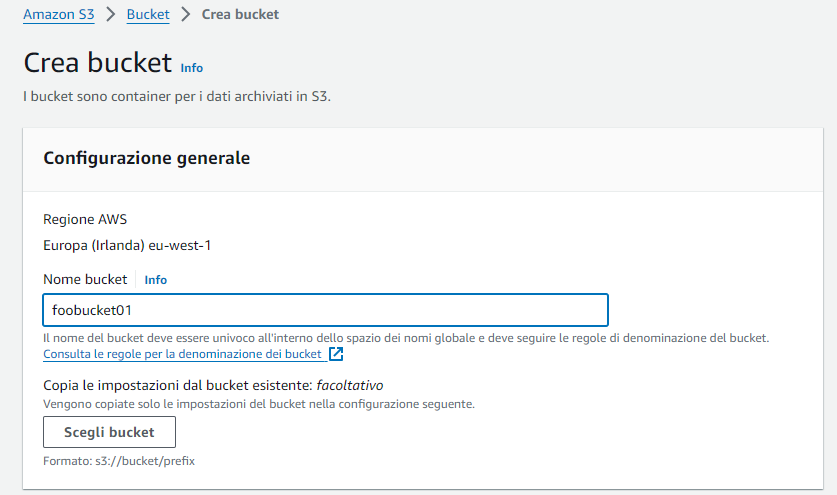
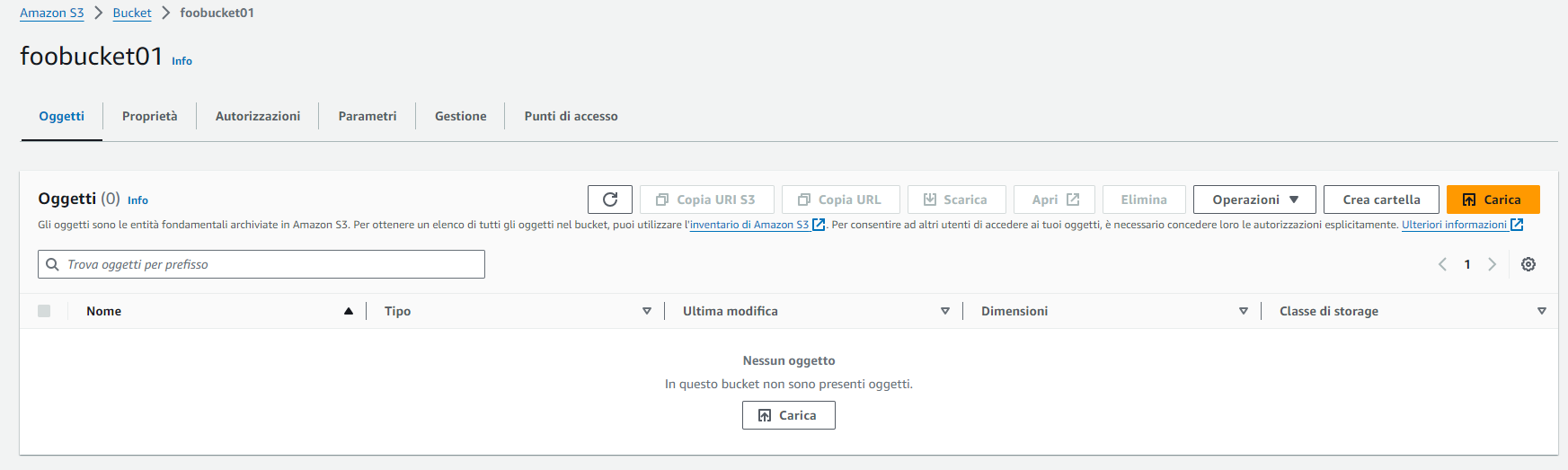
Il bucket creato comparirà in lista. Vi accediamo cliccandoci sopra.

E carichiamo i file con i dati da importare:
È ora di preparare il database.
Dalla lista dei servizi selezioniamo “Redshift”:
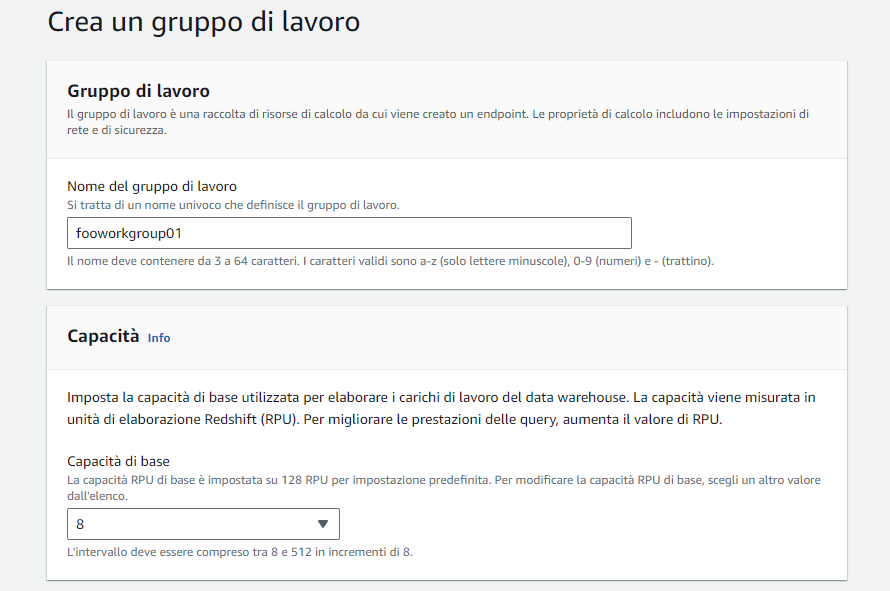
Avendo cura di selezionare la stessa regione in cui abbiamo creato il bucket, creiamo un gruppo di lavoro:

Definiamo il nome e impostiamo la capacità computazionale del job. Si noti che la capacità computazionale influisce sui costi del servizio richiesto.
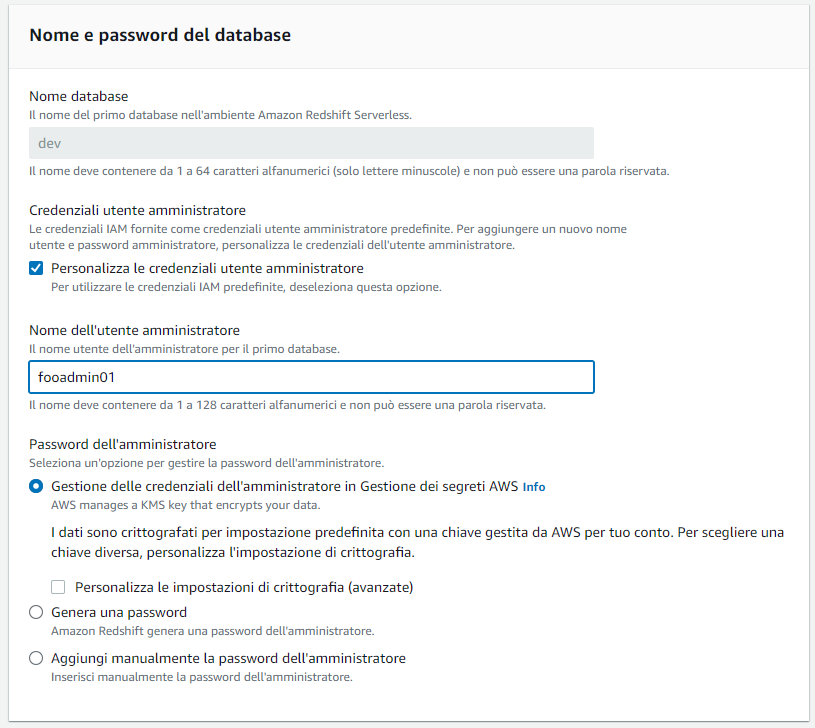
Impostiamo le credenziali di accesso al database come segue:
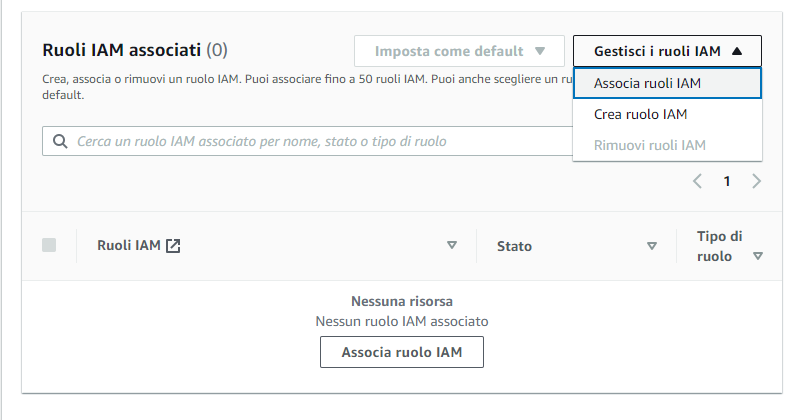
Andiamo a creare un ruolo specifico per l’accesso al bucket S3 creato in precedenza:
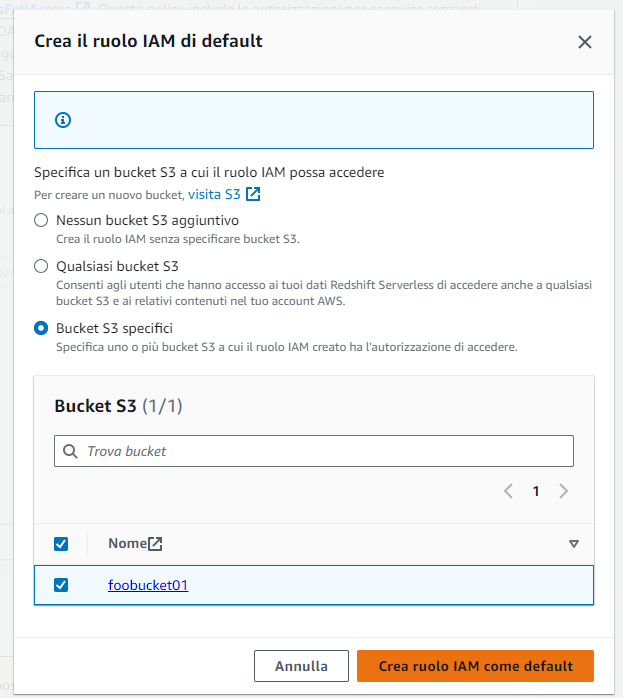
Il ruolo creato verrà associato al namespace:
Selezioniamo “Avanti” a fondo pagina.
Verifichiamo che i dati inseriti siano corretti e clicchiamo “Crea” a fondo pagina:
Dalla lista accediamo al namespace e selezioniamo “Esegui query sui dati” per accedere al Query editor:
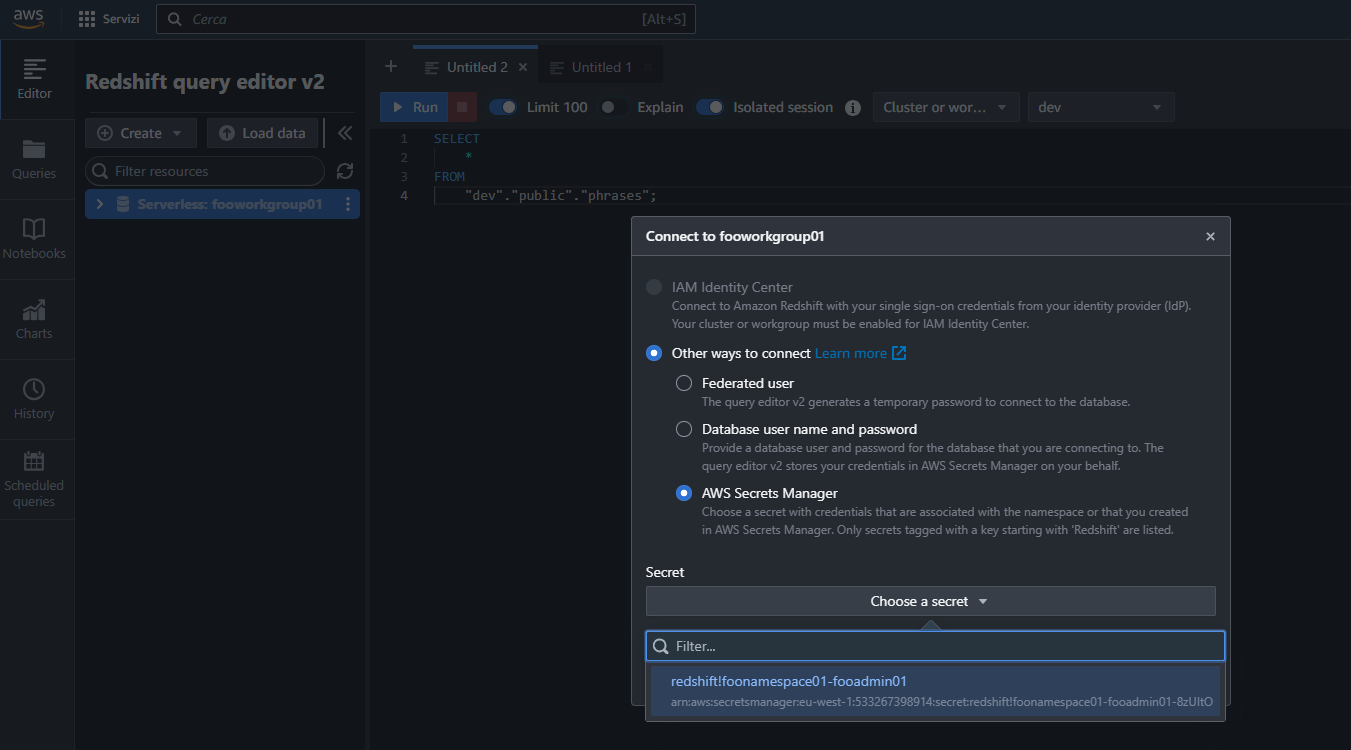
Nel query editor clicchiamo sul gruppo di lavoro e quando richiesto selezioniamo le credenziali di accesso create in precedenza per creare una connessione e accedervi:
Espandiamo tutto il ramo del database dev fino a posizionarci sul nodo tables ed eseguiamo qualche riga di SQL per creare la tabella phrases:
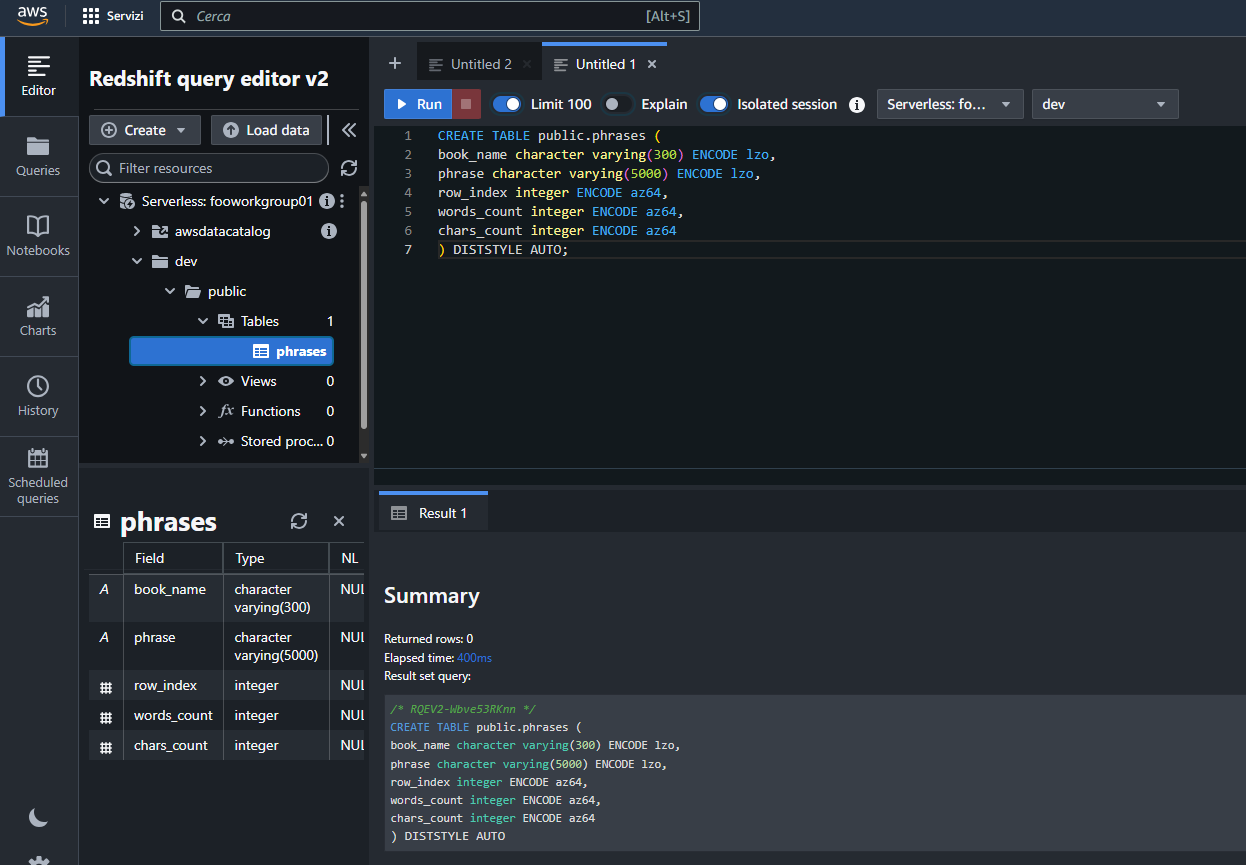
Selezioniamo “Load data” per iniziare la procedura di importazione dei dati:
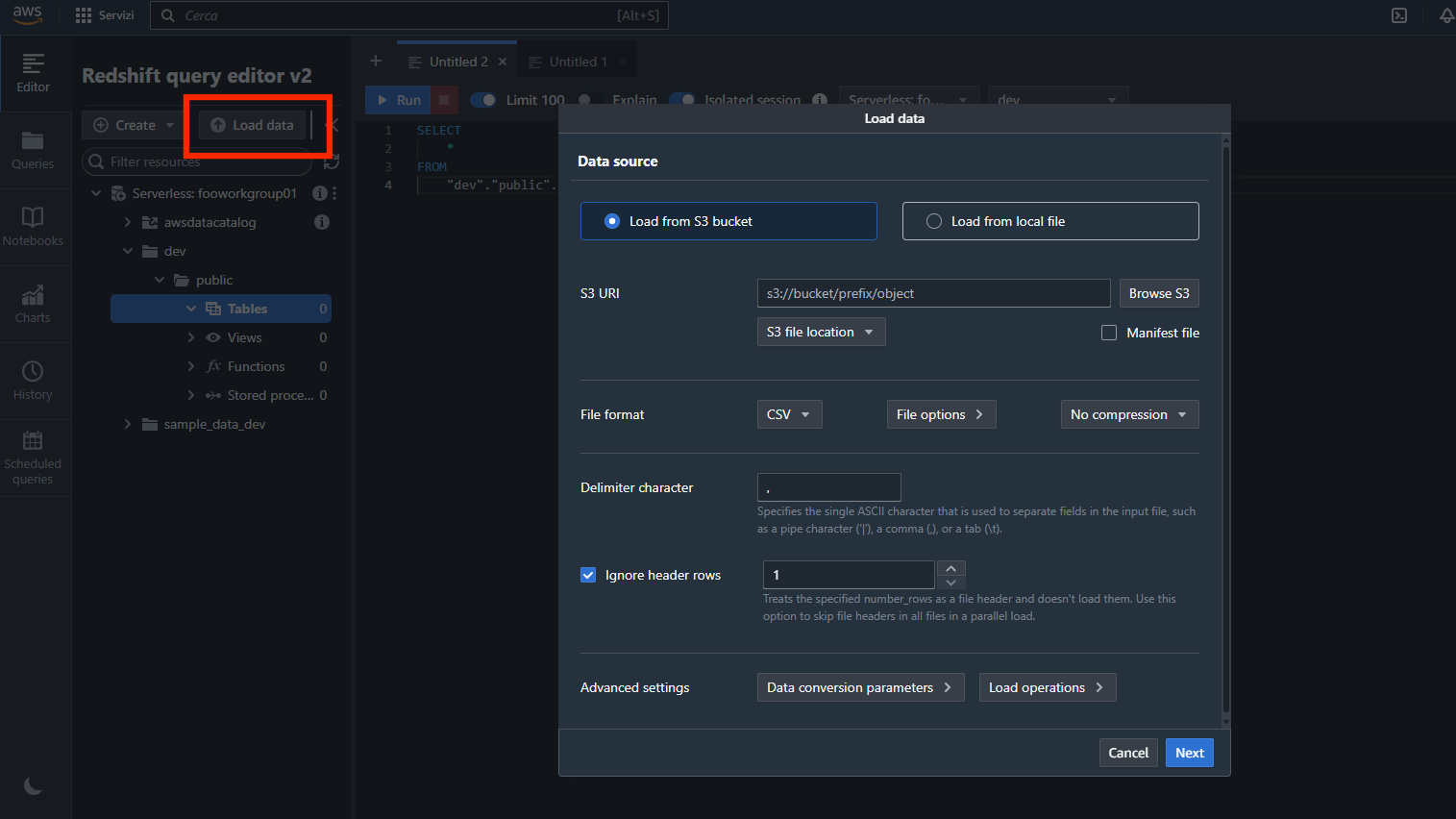
Impostiamo i parametri come segue (attenzione a impostare la stessa regione del bucket):
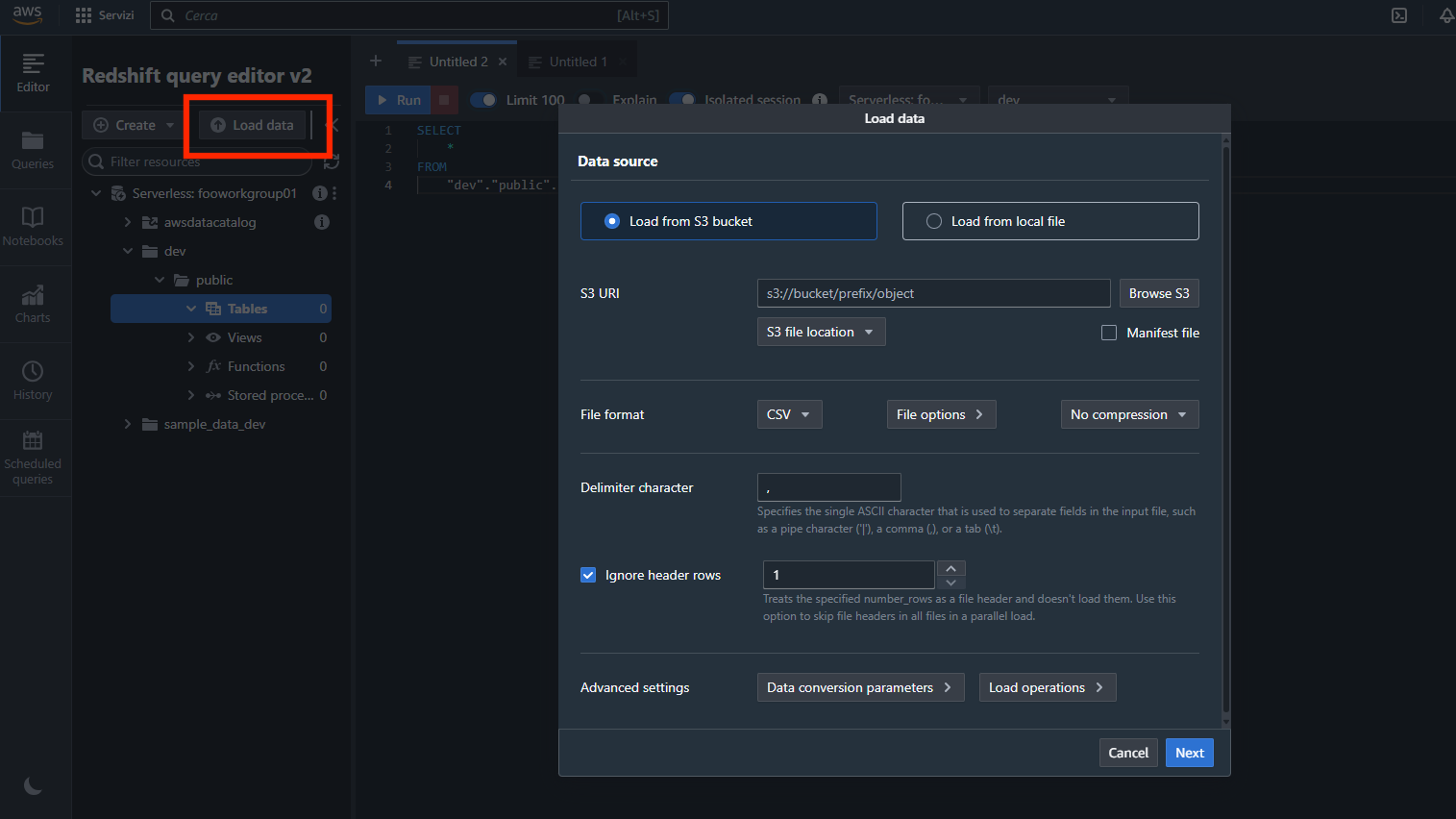
E clicchiamo “Load data”.
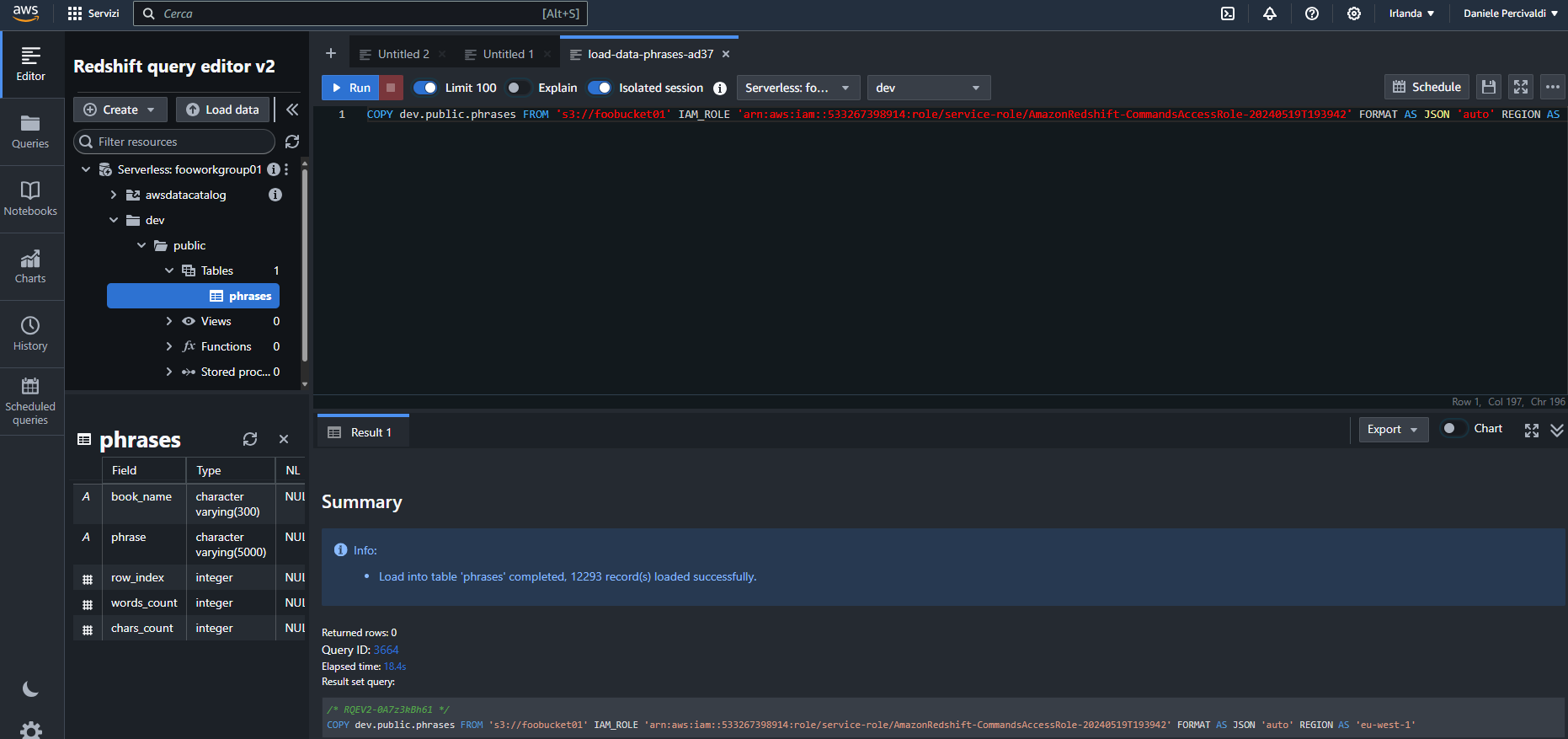
Come per il caso di Google Cloud, verifichiamo il contenuto della tabella eseguendo una semplice query:
E anche in questo caso siamo riusciti a importare i dati nella tabella.
Le nostre conclusioni
In base alle nostre esperienze riteniamo che Google Cloud si offra come un servizio più facilmente accessibile a utenti meno esperti.
Amazon Web Services sembra essere invece indirizzata a un pubblico dotato di maggiori competenze tecniche su ciascun servizio coinvolto.
Riferendoci al nostro caso infatti l’utilizzo della console di Google ha dimostrato di consentire l’accesso alle risorse desiderate più diretto rispetto agli step di configurazione necessari in AWS per fare altrettanto. Infatti in AWS la configurazione di bucket e database ha richiesto passaggi e conoscenze ulteriori (identità, permessi, secrets) che rendono più complessa la procedura.
Google inoltre mette a disposizione tutorial interattivi e una buona documentazione che aiutano chi si approccia per la prima volta al mondo dei Cloud Provider meno traumatico.