
Chaos Engineering: ingegnerizziamo il caos
Il periodo che stiamo vivendo non è dei migliori, ma abbiamo saputo reagire e pian piano stiamo rimettendo in moto tutte le attività sia lavorative che extra.
Il gruppo eXtreme Programming User Group Bergamo (1) non è stato da meno e il 5 Maggio è andato in scena il meetup virtuale con un ospite di tutto rispetto, Alberto Acerbis. E con una tematica alquanto interessante e dal nome curioso: Chaos Engineering.
Dal monolite ai microservizi
Alberto ha iniziato riportando una citazione del CTO di Amazon Verner Vogels:
Failures are given, and everything will eventually fail over time
Non c’è nulla che non si guasti, tutto prima o poi si guasta. Bisogna quindi essere pronti a gestire queste situazioni, e i motivi sono molteplici:
- Crescita esponenziale di microservizi e architetture distribuite nel cloud.
- Il Web, la rete, è cresciuto, diventando più complesso. Pensate alle miriadi di applicazioni e processi che lo compongono.
- Oggi più che mai dipendiamo tutti sempre di più da servizi web (compreso questo meetup, organizzato con Zoom e diretta streaming su YouTube).
- Data la complessità crescente dei sistemi, è molto più complesso trovare un guasto in un sistema. Rispetto a qualche anno fa, non abbiamo più tutti i pc di una rete a portata di mano. Tutto è nel cloud. Dopotutto “Riavviare Microsoft Azure non è come riavviare un server che abbiamo a disposizione nel nostro ufficio”, come dice Alberto in un esempio.
- Interruzioni di sistemi così complessi e distribuiti causano grosse perdite per le aziende.
Che cosa è successo in questi ultimi 20 anni?
Anni fa la gestione di un sistema era on-premise, ovvero si installava il sistema dal cliente e si gestiva la ridondanza (2). Come scritto prima, tutte le componenti del nostro sistema erano a portata di mano. Eventuali fermi macchina e le manutenzioni si effettuavano in loco…era quindi “facile” gestire un guasto. Le applicazioni erano grossi monoliti, certo, ma tutto era gestibile in maniera circoscritta.
Poi è arrivato il cloud.
Utenti non più connessi attraverso la classica Intranet bensì con Internet. E’ cambiato tutto. Anche le applicazioni si sono spostate nel cloud, portando ad un considerevole aumento del carico di lavoro dei servizi stessi.
E pian piano i microservizi si sono sostituiti ai monoliti.
Quali caratteristiche deve avere un’architettura per essere definita a microservizi? Alberto ci propone la risposta data a suo tempo da Martin Fowler:
We cannot say there is a formal definition of the microservices architectural style, but we can attempt to describe what we see as common characteristics for architectures that fit the label.
Non esiste una definizione formale, però vengono stilate una serie di caratteristiche comuni:
- Componentisation via services
- Organized around business capabilities
- Decentralized data management
- Products not projects
- …
- Designed for failure
Soffermiamoci sull’ultima di queste caratteristiche. Ovvero un’architettura che deve essere progettata per fallire.
Come si progetta un qualcosa affinché possa fallire?
Reactive Manifesto
Passare da monolite a microservizi non vuol dire semplicemente suddividere la logica di un software in più parti che poi magari andranno a scrivere sempre sullo stesso database. Ogni microservizio dovrà essere indipendente in tutto e per tutto (una propria interfaccia grafica, logica e database). E non è affatto semplice.
C’è bisogno di un cambio di mentalità, realizzare un’applicazione affidabile nel cloud è diverso da realizzare un’applicazione affidabile in un ambiente aziendale, molto più circoscritto. Nel 2014 è stato redatto il Reactive Manifesto (3) che descrive le caratteristiche che dovrebbe avere un sistema (immagine seguente).
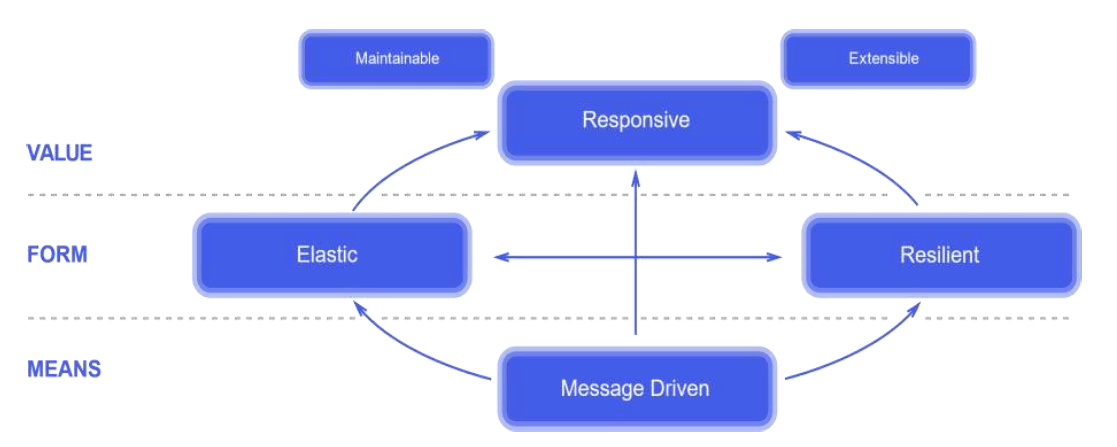
Un sistema deve essere sempre e comunque responsive, adeguarsi elasticamente al carico di lavoro, e composto da moduli (microservizi) indipendenti tra loro, senza alcuna dipendenza.
E deve essere resiliente.
Resilienza
La resilienza è la capacità di un sistema informatico di resistere sia ad eventi imprevisti sia all’uso continuato per garantire la disponibilità del servizio erogato e limitare al massimo (idealmente, in modo inavvertibile dall’utente) il degrado delle prestazioni.
Alberto ce lo ripete, un sistema nel cloud diventa qualcosa di complesso: non si tratta solo di puro software ma va tenuto conto di altre variabili quali rete server applicazioni processi e soprattutto persone. Utenti, sviluppatori, manutentori…chiunque interagisce con il sistema. Ognuno a proprio modo, in base a come concepiscono il sistema.
Resilienza in funzione di persone e la loro cultura.
Chaos Engineering
Il Chaos Engineering è una disciplina scientifica che ha come scopo quello di cercare di trovare dei fallimenti di un sistema.
E il modo migliore è attraverso esperimenti che è bene effettuare su un software organizzato in moduli che siano il più possibile indipendenti. Questo perché iniettare turbolenze può compromettere l’unità sotto esame, ma solo quella e non l’intero sistema.
Un’altra definizione, presa da Principles of Chaos Engineering (4), recita
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production
Ovvero una disciplina scientifica che permette di sperimentare il sistema al fine di ottenere confidenza nella capacità della turbolenze iniettata in condizioni di produzione.
Ancora una volta, lo scopo finale è trovare le debolezze di un sistema, o in gergo dark debt (5). Il “debito oscuro”non è riconoscibile al momento della creazione. bensì deriva dalle interazioni impreviste di hardware o software con altre parti del framework. Il dark debt è invisibile fino a quando un’anomalia rivela la sua presenza.
Storia
Sebbene la disciplina sia molto giovane, ha delle basi solide risalenti addirittura all’epoca di Galileo Galilei. Dalle slide (6) del talk di Alberto:

Nel 2000 Jeff Robbins, a.k.a. Master of Disaster, era responsabile dell’infrastruttura in Amazon. Ma anche aspirante vigile del fuoco. Questa sua aspirazione è stata fondamentale per la nascita del Game Day, mezza giornata dedicata all’acquisizione di familiarità del sistema a fronte di iniezioni di turbolenze al fine di migliorare la resilienza. Con un occhio di riguardo non solo al software ma anche alle interazioni delle persone con il software. L’obiettivo di una giornata di gioco è esercitarsi su come te stesso, la tua squadra e il tuo sistema di supporto si occupa di “condizioni di turbolenza” turbolente nel mondo reale. Creazione di resilienza attraverso la distruzione.
Dopotutto, come dice Jeff Robbins:
You don’t choose the moment, the moment chooses you. You only choose how prepared you are when it does.
Che è di fatto la filosofia di ogni vigili del fuoco, che spende l’80% del tempo all’addestramento ed essere talmente preparato che domare un incendio dovrebbe essere automatico.
Chaos experiment vs Testing
Se ci pensiamo bene, fare esperimenti di caos e fare attività di testing sembrano simili tra loro.
Quando testiamo un software, partiamo da conoscenze note del sistema. Applichiamo il TDD e lo sviluppiamo. Si ha consapevolezza quindi: conosciamo il sistema, formuliamo ipotesi e facciamo in modo di validarle.
Per il chaos experiment il discorso è diverso. Si fanno esperimenti su una porzione limitata del sistema. Man mano che facciamo esperimenti creiamo nuova conoscenza. Allarghiamo man mano il mio raggio d’azione, proseguiamo con gli esperimenti finché non troviamo una debolezza. Partendo da un’ipotesi, con chaos experiment si va avanti finché non smentisco l’ipotesi.
Quando troviamo la debolezza, l’errore, abbiamo scoperto qualcosa di nuovo. Ecco che quindi occorre fare qualcosa affinché il sistema migliori e diventi ancora più robusto.
Di seguito riporto un’immagine delle fasi del Chaos Engineering
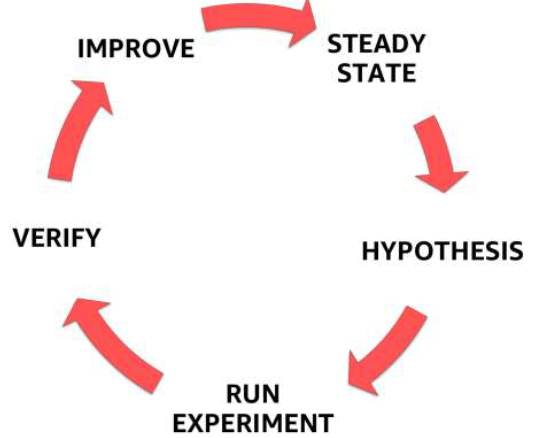
Nella parte finale del meetup Alberto ha mostrato una demo di chaos experiment. Quattro macro step:
- Utilizzare chaos experiment per per esplorare e scoprire punti deboli nel sistema.
- Utilizzare chaos experiment per scoprire e iniziare ad analizzare eventuali punti deboli emersi nel sistema.
- Una volta terminata l’analisi, è tempo di applicare un miglioramento al sistema (se necessario).
- Validazione: il chaos experiment diventa un chaos test per rilevare se la debolezza è stata effettivamente superata.
Benefici del Chaos Engineering
Prima di salutarci, Alberto riporta quelli che econdo lui sono i benefici della pratica di questa disciplina:
- Chaos Engineering ci aiuta a scoprire le incognite di un sistema e porre rimedio prima che si verifichino in produzione ( magari alle 3 del mattino durante il fine settimana) – quindi, miglioramento non solo della resilienza ma anche delle ore di sonno.
- Praticare con successo Chaos Engineering genera molti più cambiamenti del previsto, e questi sono per lo più culturali. Probabilmente il più importante di questi riguarda una naturale evoluzione verso una cultura del no-blaming: il “Perché l’hai fatto?” si trasforma in un “Come possiamo evitare di farlo in futuro?”. Abbandonare approcci accusatori porta con il tempo ad un grande risultato: avere un team più felice, che quindi lavora in maniera più efficiente e quindi con più successo.