Categorie articolo: Learn
Reactive Programming: dalle origini alle librerie Reactor e RxJava
3 Dicembre 2020 - 7 minuti di lettura
RxJava [2] si basa, per la sua implementazione, su concetti (Design Pattern) quali Observer, Subject e Scheduler mentre Reactor, anche perché più recente, implementa la specifica degli stream presente nella versione 9 del JDK [3].
Il sistema rimane reattivo con carichi di lavoro variabili. I sistemi reattivi possono reagire alle variazioni della velocità di input aumentando o diminuendo le risorse allocate per servire questi input. Ciò implica progetti che non hanno punti di contesa o colli di bottiglia centrali, con la possibilità di frammentare o replicare componenti e distribuire input tra di loro. I sistemi reattivi supportano algoritmi di ridimensionamento predittivi e reattivi fornendo misure di performance dal vivo pertinenti. Raggiungono l’elasticità in modo economico su piattaforme hardware e software di largo consumo.
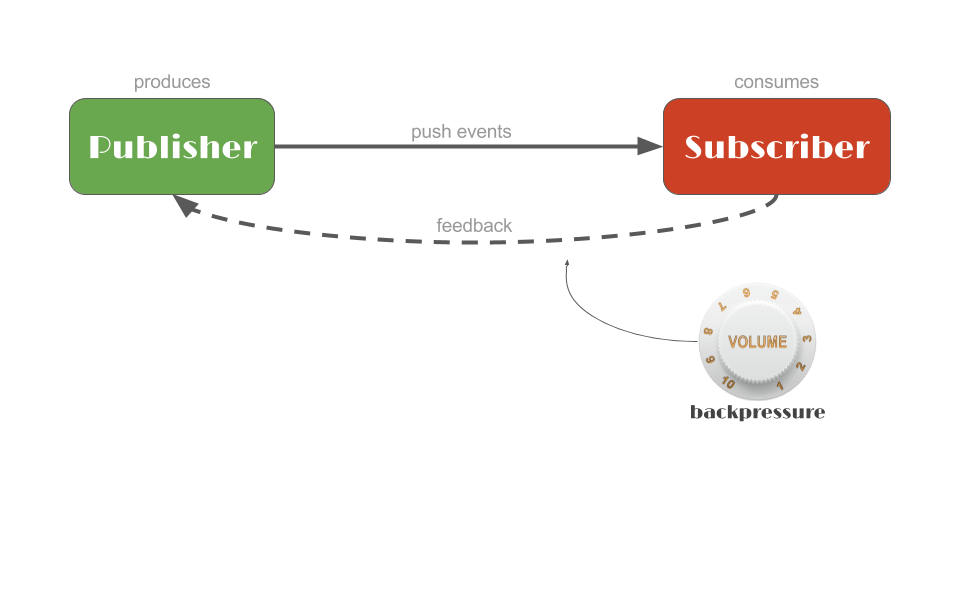
I sistemi reattivi si basano sul passaggio di messaggi asincroni per stabilire un confine tra i componenti che garantisce accoppiamento libero, isolamento e trasparenza della posizione. Questo limite fornisce anche i mezzi per delegare gli errori come messaggi. L’impiego del passaggio esplicito dei messaggi consente la gestione del carico, l’elasticità e il controllo del flusso modellando e monitorando le code dei messaggi nel sistema e applicando la contropressione quando necessario. La messaggistica trasparente della posizione come mezzo di comunicazione consente alla gestione del fallimento di funzionare con gli stessi costrutti e la stessa semantica in un cluster o all’interno di un singolo host. La comunicazione non bloccante consente ai destinatari di consumare risorse solo quando sono attivi, riducendo il sovraccarico del sistema.
<dependency> <groupId>io.projectreactor</groupId> <artifactId>reactor-core</artifactId> <version>3.0.5.RELEASE</version> </dependency>
Un esempio di inizializzazione di Flux è:
Flux just = Flux.just("1", "2", "3");
Mono<String> just = Mono.just("foo");
List<Integer> elements = new ArrayList<>(); Flux.just(1, 2, 3, 4) .log() .subscribe(elements::add);
Flux<Integer> evenNumbers = Flux .range(min, max) .filter(x -> x % 2 == 0); // i.e. 2, 4 Flux<Integer> oddNumbers = Flux .range(min, max) .filter(x -> x % 2 > 0); // ie. 1, 3, 5
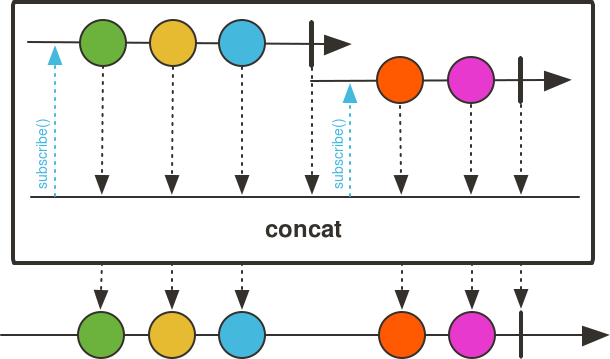
Flux<Integer> fluxOfIntegers = Flux.concat(
evenNumbers,
oddNumbers);
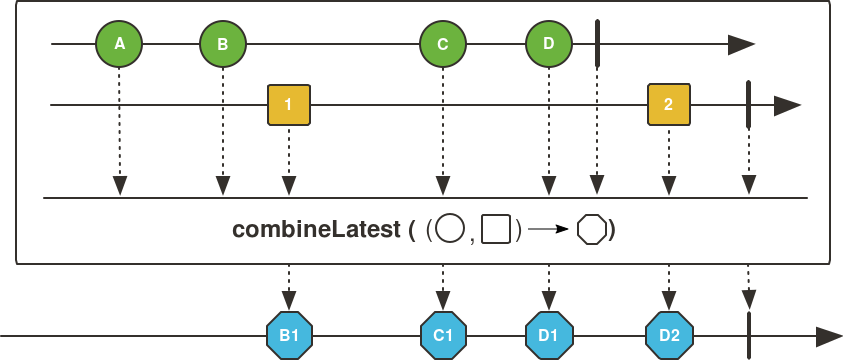
Flux<Integer> fluxOfIntegers = Flux.combineLatest( evenNumbers, oddNumbers, (a, b) -> a + b);
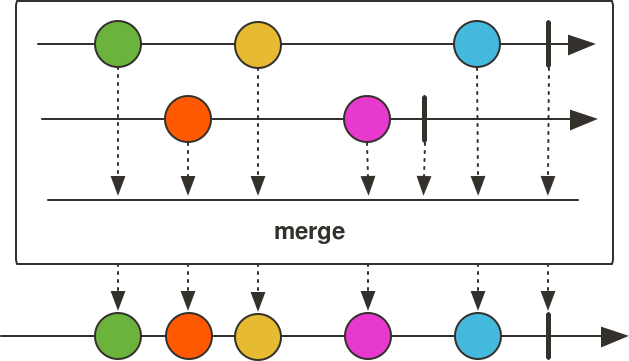
Flux<Integer> fluxOfIntegers = Flux.merge( evenNumbers, oddNumbers);
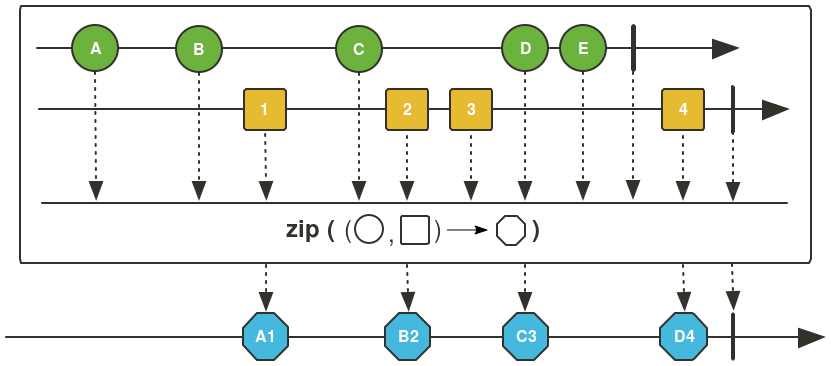
Flux<Integer> fluxOfIntegers = Flux.zip( evenNumbers, oddNumbers, (a, b) -> a + b);