
Categorie articolo: Learn
I misteri della Programmazione Funzionale
23 Febbraio 2022 - 9 minuti di lettura
Programmazione funzionale! Per noi che abbiamo sempre programmato prevalentemente a oggetti la programmazione funzionale rappresenta uno spauracchio.
Da un lato termini come “Pure Functions”, “Referential Transparency”, “Algebraic Data Type”, “Functor”, “Monad” possono intimorire, ma allo stesso tempo hanno il fascino dell’esotico, di un diverso modo di pensare, di un incontro con una diversa cultura.
Da questa curiosità è nata l’idea di organizzare una gilda per apprendere i rudimenti della programmazione funzionale e quale miglior guida per esplorare questo nuovo territorio se non quella di Matteo Baglini il quale ci ha introdotto a questo nuovo paradigma. Beh, nuovo per noi, ma che risale in effetti agli anni ’50 e precede di molto la programmazione orientata agli oggetti.
Indice dei contenuti:
Se il paradigma funzionale viene spesso visto come alternativo al paradigma a oggetti o al più complementare, a ben vedere è un diverso modo di rispondere agli stessi problemi.
La difficoltà maggiore quando si sviluppa un’applicazione è il rapido crescere della complessità e il carico cognitivo necessario per comprenderla e gestirla. La continua dinamicità dei requisiti e delle persone coinvolte nello sviluppo richiedono che il codice sia chiaro, comprensibile, facilmente manipolabile, modificabile e adattabile a nuove esigenze. Facile a dirsi, ma nella realtà accade assai di rado.
L’approccio a un problema complesso è sempre lo stesso: suddividerlo combinando tante piccole soluzioni semplici.
La programmazione orientata agli oggetti identifica appunto gli oggetti come elementi dotati di un comportamento relativamente semplice e quindi comprensibile, che combinati danno origine a comportamenti più complicati.
La programmazione funzionale dà la sua particolare risposta al problema, ponendo le funzioni pure come elemento base per comporre comportamenti più complicati.
Una funzione, un metodo, una procedura, sono un insieme di righe di codice che, dati dei valori in input, generano dei valori di output. Se ci limitassimo all’associazione tra valori di input e output, senza interessarci di come questi valori sono calcolati, un metodo sarebbe relativamente semplice da comprendere e da utilizzare.
I problemi però subentrano quando un metodo ha dei side effect, ovvero non si limita a produrre un output ma:
Questi side effect sono “nascosti” nel senso che non sono esplicitati nella firma del metodo (spesso nemmeno nel nome) e pertanto ci costringono a guardare all’interno del metodo stesso per sapere quali sono e soprattutto ci costringono a tenerne conto quando combiniamo più metodi tra di loro.
Se un metodo modifica lo stato, quando lo utilizziamo in combinazione con un altro metodo che usa lo stesso stato, dobbiamo tenere in considerazione questa dipendenza nascosta. Al crescere di queste dipendenze, cresce il carico cognitivo a cui siamo soggetti per tenere a mente queste relazioni e comprendere il comportamento complessivo.
Quanto sarebbe più semplice se non ci fossero side effect e se il risultato di un metodo dipendesse solo dai valori di input, senza dover tenere conto dei cambiamenti di stato, delle operazioni di I/O, delle eccezioni? Combinare i comportamenti diventerebbe molto più semplice, perché possiamo limitarci a considerare l’output di un metodo come input del successivo, senza dover tenere conto di nient’altro.
Questo è esattamente ciò si prefigge la programmazione funzionale: utilizzare funzioni pure, semplici da comprendere e facili da combinare, limitando l’applicazione di side effect in pochi punti ben precisi, per poterli gestire al meglio. O almeno questa è la nostra interpretazione molto semplificata della ragione alla base della programmazione funzionale.
Un corollario del fatto che si evita di modificare lo stato e i parametri di input è che i dati sono di fatto immutabili. Esplicitare che un dato sia immutabile è un altro grande aiuto nella semplificazione del ragionamento, perché non dobbiamo preoccuparci se un dato è cambiato e come, anche se apparentemente imporre l’immutabilità dei dati può sembrare limitante.
Se l’assenza di side effect ci semplifica enormemente la vita, bisogna anche ammettere che un programma senza side effect non è poi molto utile.
Il problema diventa quindi quello di “gestire” i side effect, isolarli in punti ben precisi e identificabili del codice, facendo in modo che il resto delle funzioni siano facilmente combinabili e ricombinabili, senza doversene preoccupare.
E qui entrano in scena le monadi, molto semplicemente uno strumento per gestire i side effect quando si compongono tra loro più funzioni.
Facciamo l’esempio semplice della monade Option. Supponiamo di avere diverse funzioni che gestiscono un numero intero sia come parametro d’ingresso che di uscita. Supponiamo anche che alcune di queste siano “funzioni parziali” vale a dire che per alcuni valori di input non definiscono un corrispondente valore di output, ma restituiscono null.
Nella programmazione imperativa, ogni volta che combiniamo due funzioni, dobbiamo gestire il caso in cui il valore sia null. Ciò che facciamo solitamente è inserire molti If – magari annidati tra loro – nella sequenza di funzioni, anche per gestire il caso null. La monade Option ha proprio lo scopo di gestire la presenza o l’assenza di un valore. Trasformando le nostre funzioni di interi in funzioni che accettano e restituiscono un Option, possiamo combinare le funzioni disinteressandoci del caso Option, perchè sarà la monade stessa a prendersi in carico la responsabilità di gestirlo. Il risultato sarà una sequenza semplice e lineare di combinazioni di funzioni, facile da leggere e comprendere, potendo ignorare il caso null, dato che la sua gestione è demandata e resa esplicita dall’uso di Option.
Analogo discorso si può fare per la gestione delle eccezioni con la monade Try, oppure per i cambi di stato con la monade State, o per la gestione della scrittura in un file o su standard output con la monade Write. Scala mette a disposizione altre monadi utili, e altrettante possono essere definite da noi stessi.
Il modo di gestire le monadi, quando si compongono funzioni, è sempre lo stesso, rendendo la composizione delle funzioni molto semplice e standardizzata.
E se vi stavate chiedendo come trasformiamo le nostre funzioni parziali di interi in funzioni di Option, per questo ci sono i metodi map e flatmap della monade che rendono la trasformazione trasparente e indipendente dal tipo di monade.
In fase di preparazione del corso, il coach Matteo Baglini ci ha fornito un repository Git su cui abbiamo potuto svolgere dei brevi esercizi per prendere confidenza con i rudimenti di Scala.
Abbiamo fatto ampio uso delle breakout room per sperimentare in gruppi più piccoli con il supporto del coach e poi confrontarci insieme.
Dopo aver appreso i concetti base abbiamo iniziato a lavorare con dei kata mirati che ci hanno permesso di vedere come affrontare problemi più complessi spostando il focus sulla parte architetturale.
Al termine di ogni mattinata abbiamo potuto lasciare il nostro feedback sui concetti affrontati, evidenziando ciò che ci ha colpito e ciò che invece ha lasciato qualche perplessità.
I primi esercizi si sono concentrati sugli “Algebraic Data Types” (ADT), strutture dati immutabili usate per modellare i dati sfruttando la composizione.
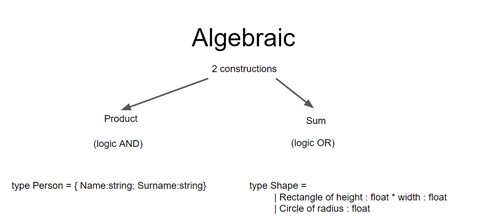
Le due strategie di composizione più comuni che abbiamo visto sono “Product Type” e “Sum Type” e si possono mixare tra loro a piacimento. Di seguito un esempio scritto in Scala:
type Prodcut = { a: number, b: string }
type Sum = [ number, string ] | "Or" | Product
type ADTs = Product & Sum
I “Product Type” sono una struttura dati “raccoglitore” per diversi tipi. In scala si rappresentano con delle case class, in C con delle struct.
Un ordine dal fruttivendolo definito da un frutto insieme alla sua quantità potrebbe essere scritto così:
case class Order(fruit: Fruit, quantity: Int)
I “Sum Type“, anche detti “Union Type”, rappresentano invece la scelta tra tipi diversi di quell’insieme. L’insieme dei frutti dell’esempio precedente lo definiamo con un’interfaccia Frutto che viene estesa dai frutti di quell’insieme. In questo caso un frutto può essere o una mela o una banana:
sealed trait Fruit case class Apple() extends Fruit case class Banana() extends Fruit
Durante il corso abbiamo sperimentato che un ottimo punto di partenza per risolvere un problema con la Programmazione Funzionale è proprio quello di partire dalla definizione dei tipi tramite Sum e Product types.
Dopo aver modellato i dati con gli ADT si passa quindi a definire la firma delle funzioni per modellarne il comportamento rimandando a una seconda fare i dettagli implementativi.
Altro concetto chiave è la separazione della descrizione del programma dall’esecuzione.
Per capirne l’utilità bisogna fare un po’ di astrazione, ma fondamentalmente si vuole mantenere separate le logiche di esecuzione dalle singole funzioni che descrivono i comportamenti. In questo modo si semplifica/favorisce la composizione.
Prendiamo come esempio il seguente codice e due diverse esecuzioni:
//definizione dei comportamenti (programma) def num(x: Int): Expr def plus(x: Expr, y: Expr): Expr def times(x: Expr, y: Expr): Expr //composizione val program = times(plus(num(1), num(1)), num(2)) //esecuzione 1 def eval(e: Expr): Int eval(program) // -> 4 //esecuzione 2 def evalPrint(e: Expr): String evalPrint(program) // -> "((1 + 1) * 2)"
Il programma descritto da program può essere eseguito in modi diversi per ottenere risultati anche molto differenti. Eseguendo program con la funzione eval il risultato è il valore rappresentato dall’espressione, mentre eseguendolo con la funzione evalPrint quello che otteniamo è una stringa che rappresenta l’espressione stessa.
Ciò che si nota in questo esempio è che il funzionamento del programma si ottiene componendo funzioni più piccole/semplici, strategia che viene comunque sempre utilizzata per ottenere risultati diversi.
Sarebbe bello e sarebbe anche tutto più semplice se potessimo usare solo funzioni pure, purtroppo però esistono degli effetti (errori, risorse mancanti, input errati) e dobbiamo gestirli.
Per questo il mondo della Programmazione Funzionale ci mettere a disposizione una serie di strumenti che ci permettono di incapsulare gli effetti e di traslare le nostre funzioni pure, senza effetti, al mondo “effectful” riuscendo a mantenere i vantaggi della composizione anche in quelle situazioni dove non sarebbe possibile.
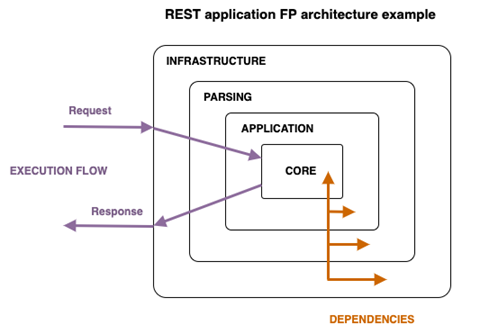
In un’architettura funzionale, la parte “core” è costituita dagli ADT che modellano gli oggetti di dominio. Il layer di Application invece, contiene le funzioni che descrivono i comportamenti del sistema. La parte di Infrastructure ha il compito di raccogliere gli I/O derivanti dalla comunicazione con il mondo esterno (API rest, input utente, database, file, ecc). Il layer di Parsing serve a fare comunicare i due layer di Application e Infrastructure, parsando gli input e generando i rendering degli output.
Una delle idee alla base della Programmazione Funzionale è il concetto “forward only” ovvero un flusso di esecuzione continuo, indipendentemente da possibili situazioni di errore che potrebbero verificarsi durante l’esecuzione del codice.
Non capita spesso di vedere lanciare eccezioni, ma capita di dover gestire componenti terzi che non rispecchiano il paradigma funzionale. In questi casi l’errore viene inglobato in uno specifico “effect” e propagato alle funzioni successive.
Per applicare la Programmazione Funzionale siamo obbligati a usare quei pochi linguaggi nati per essere utilizzati con questo approccio?
Possiamo applicare i concetti principali con quasi tutti i linguaggi; alcuni di questi si stanno approcciando sempre di più alla Programmazione Funzionale, introducendone la sintassi e i costrutti base. Sono disponibili diverse librerie per estendere le capacità dello specifico linguaggio.
Ovviamente un linguaggio nato come funzionale puro permette di esprimere il vero potenziale di questo paradigma.
Anche utilizzando linguaggi non funzionali, applicando i concetti base, ci si accorge che il codice scritto risulta più conciso e le logiche che esprime sono più chiare da cogliere e quindi anche da modificare se necessario.
Lavorando con la Programmazione Funzionale abbiamo apprezzato un altro vantaggio, l’assenza di “race conditions“. Lo stato è sempre locale nella singola funzione e non può essere modificato dall’esterno.
Per iniziare a beneficiare di alcuni dei vantaggi della Programmazione Funzionale non è necessario cambiare tutta l’architettura esistente. Anche solamente eseguendo un “refactoring” di un metodo complesso usando dati immutabili e componendo più funzioni pure, permette un primo approccio alla Programmazione Funzionale.







