
Bot Telegram, AI e Machine Learning – VisualBOT
Alla nostra prima unconference del 2021 sono stati trattati tanti argomenti, e tra questi c’è stata la presentazione di VisualBOT.
Di che si tratta?
Di un progetto di “Visual Information Processing and Management” realizzato dal nostro Andrea Caglio insieme a Orazio Carissimi, Andrea Ponti e Simone Rizza, tre suoi compagni del corso di laurea di informatica dell’Università degli Studi di Milano-Bicocca.
A cosa serve VisualBOT, il nome di questo bot Telegram? Ricevuto in input l’immagine di un capo di abbigliamento, ne riconosce il tipo (una maglietta, una giacca, un jeans ad esempio) sfruttando alcuni processi di Machine Learning (ML) e Artificial Intelligence (AI).
In questo articolo vi racconterò le fasi del progetto realizzato dai ragazzi: creazione e preparazione del dataset, la classificazione dei dati, gli algoritmi per stabilire la similarità dell’immagine, le logiche di correzione delle immagini e infine la creazione del bot Telegram.
Il primo paragrafo è dedicato alle tecnologie coinvolte nella realizzazione di VisualBOT.
Buona lettura.
Tecnologie utilizzate
Per il backend è stato utilizzato il linguaggio Python versione 3.7 e integrato con del codice Matlab per la gestione e correzione delle immagini. Come ambiente di sviluppo è stato scelto l’ambiente PyCharm, un IDE della famiglia Jetbrains.
Creazione del Dataset
Il dataset di partenza è un dataset di immagini raccolto dall’e-commerce cinese JD.com che contiene circa 10.000 istanze relative a prodotti di abbigliamento. Un file .csv raggruppa le informazioni relative a ciascuna foto in cui sono indicati nome, classe e gruppo. Dall’estrapolazione dei dati fatta attraverso uno script Python è emerso che fossero presenti circa 9690 classi e 359 gruppi, ognuno da etichettare manualmente. Un lavoro oneroso ma necessario per riportare nel file .csv le categorie dei prodotti (ad esempio “Giubbotto”, “Asciugacapelli”, “Frigorifero”).
Successivamente sono state estratte manualmente tre macro-categorie, tra tutte quelle trovate:
- Jacket: 3069 immagini.
- Pants: 8430 immagini.
- Shoes: 12917 immagini.
Per ognuna delle tre macro-categorie è stato necessario estrarre delle sottocategorie, ad esempio “Adult Jacket”, “Baby Jacket”, “Suit Jacket” e “Swetshirt” per la categoria “Jacket”.
Preparazione del dataset
Come rendere operativo il dataset appena creato? Occorre eseguire una serie di operazioni, vediamo quali.
Segmentazione
In questa fase l’immagine viene partizionata per estrapolare le regioni significative con lo scopo di rimuovere lo sfondo e mantenere le componenti significative per individuare nel caso specifico il capo di abbigliamento.
Il modello utilizzato è U-net, una rete convoluzionale sviluppata inizialmente per scopi biometrici ma che può essere riadattata per altri progetti. La metrica utilizzata per estrapolare le regioni è alpha score (α), e tanto più è grande questo valore tanto più spazio occupa l’elemento da estrarre. Le seguenti immagini chiariscono quanto appena scritto:

Estrazione delle feature
Nella seconda fase di estrazione delle feature viene utilizzata un’altra rete neurale convoluzionale, VGG16, basata e addestrata su un dataset di circa 14 milioni di immagini appartenenti a circa 1000 classi differenti. Le feature estratte verranno poi utilizzate da una rete neurale per la classificazione delle immagini, spiegato in seguito.
Data Augmentation
In questa fase si cerca di bilanciare il numero di immagini precedentemente categorizzate nella fase di creazione del dataset. Tramite operazioni di oversampling – generazione di immagini random – e undersampling – rimozione di immagini random – si va quindi a bilanciare il peso di ciascuna categoria e sottocategoria.
Istogrammi di colore
Vengono creati istogrammi di colore per ciascuna immagine, estrapolando la maschera di interesse e creando quindi il grafico dei colori presenti.
Estrazione delle texture
Questa operazione viene fatta utilizzando la matrice di co-occorrenza (GLCM Gray – Level Co-Occurrence Matrix) che è composta dai valori di grigio dei singoli pixel usati appunto per misurare diverse proprietà – texture appunto – dell’immagine quali il contrasto, la luminosità, l’omogeneità, l’energia e la correlazione.
Estrazione degli edges
In questa fase si estraggono le proprietà relative alla forma delle immagini. Nel caso specifico sono state fatte due estrazioni, una per i contorni orizzontali e l’altra per i contorni verticali.
Classificazione dei dati
Per questa operazione è stato realizzato un semplice modello di rete neurale convoluzionale ad-hoc per elaborare input matriciali anziché vettoriali, a differenza delle reti neurali. L’architettura è composta da 3 layer convoluzionali e 3 layer di pooling seguiti da un ulteriore strato Dense il quale, grazie ad una funzione softmax, è in grado di individuare la categoria di appartenenza di un’immagine.
Questo modello ha ottenuto sì delle buone prestazioni, ma non soddisfacenti per lo scopo finale. E’ stato perciò sviluppato un modello più complesso basato sulle feature estratte da VGG16 tramite la tecnica di ML Trasfer Learning.
In sintesi, dal modello pre-allenato VGG16 sono state estratte le ultime feature date poi in ingresso ad una rete neurale per la classificazione delle immagini:
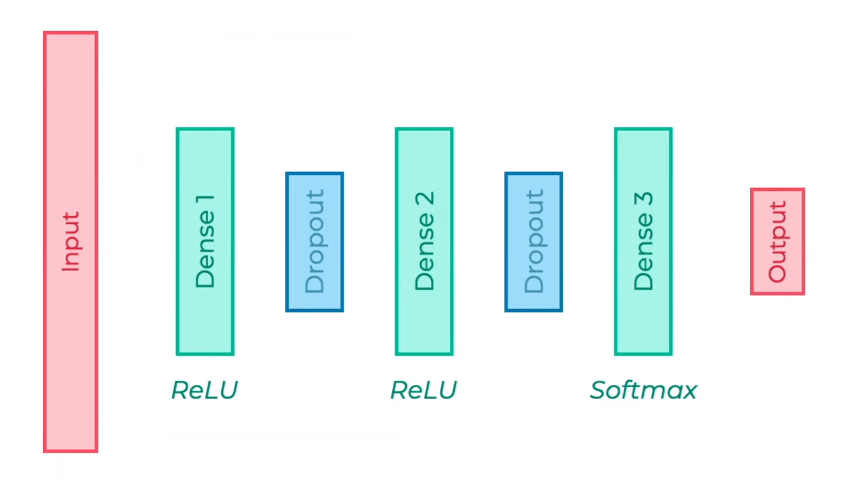
Questa nuova architettura di rete ha ottenuto un miglioramento a livello di prestazioni anche grazie al concetto di ottimizzazione Bayesiana.
Similarità delle immagini
Obiettivo di questo task è, data una certa immagine, restituire un insieme di immagini simili prese dal dataset. Il modello utilizzato è il K-nearest neighbors che calcola la distanza euclidea tra i k (dove k=10) elementi, più precisamente immagini, più vicini nello spazio.
Inizialmente sono stati fatti test con il bot per calcolare la distanza tra immagini considerando le feature estratte attraverso l’algoritmo VGG16, con risultati non soddisfacenti (le immagini non erano visivamente simili), si è allora provato a considerare le texture ma ancora una volta i risultati ottenuti non hanno soddisfatto (la texture di una scarpa e di un giubbotto possono essere le stesse, ma i capi d’abbigliamento ovviamente no).
Stesso discorso per i test fatti considerando gli edges, ovvero i contorni.
Si è deciso di cambiare il modello, o meglio la metrica utilizzata. Anziché la distanza euclidea utilizzare la correlazione utilizzando come caratteristica delle immagini gli istogrammi di colore. Si è ottenuto un netto miglioramento, e da questo sono stati creati tre diversi modelli, uno per ogni macro-categoria: Jacket, Pants e Shoes.
Correzione delle immagini
Con questa funzionalità è possibile rilevare e correggere le immagini in base a tre criteri di qualità (implementati in altrettanti script Python):
- Sfocatura: lo script calcola la varianza della matrice laplaciana dell’immagine data in input.
- Luminosità: calcolata seguendo tre canali: L (luminosità) A (colori dal verde al rosso) e B (colori dal blu al giallo).
- Rumore: è stato calcolato il rumore gaussiano.
Per ognuno dei criteri di qualità Andrea e compagni hanno stabilito delle soglie ottimali, sotto le quali rilevare appunto un problema di qualità, raccogliendo dati di test eseguiti su un campione di immagini prese dal dataset e date in pasto al bot Telegram:
- Sfocatura: varianza matrice < 100.
- Luminosità <= 0.4.
- Rumore gaussiano > 15.
Per migliorare i problemi legati alla luminosità è stato implementato uno script Matlab integrato al codice del bot utilizzando un filtro bilaterale che agisce sul canale di luminosità, mentre per quel che riguarda la correzione del rumore è stato implementato uno script in Python per fare attività di denoising di immagini con l’aiuto della libreria OpenCV.
Il bot Telegram VisualBOT
Le fasi precedentemente descritte sono state propedeudiche alla realizzazione del bot Telegram.
Per la creazione vera e propria del bot è stato usato BotFather, anch’esso un bot (manco a farlo apposta) tra i più diffusi ed apprezzati.
Come funziona?
E’ semplicissimo, bisogna innanzitutto cercare “@BotFather” sfruttando la funzione di ricerca dell’app di Telegram dopodiché avviare l’applicazione ufficiale BotFather. Tra le varie operazioni, il bot permette appunto di creare un nuovo bot tramite il comando /newbot. Viene richiesto un nome, che deve terminare con _bot, e uno username per il nuovo bot. Al termine della procedura di creazione verrà pubblicata una chiave HTTP API da usare per controllare il bot in remoto tramite un’applicazione esterna che andrà dichiarata in Telegram.
La principale libreria usata nell’implementare VisualBOT è telepot per gestire:
- Le callback per gestire l’interazione con l’utente il quale, per rispondere a delle domande del bot, utilizza dei pulsanti “Yes\No”.
- Il riconoscimento delle diverse tipologie di messaggi, sia testo che foto (jpg, png e bitmap i formati supportati).
- L’implementazione di alcuni comandi.
VisualBOT in azione
Il bot, data in ingresso un’immagine, è in grado di riconoscere, applicando i criteri di similarità descritti, se appartiene ad una delle tre macro-categorie e in caso a quale sotto-categoria, chiedendo poi all’utente se voglia visualizzare immagini simili (ricordo, sempre prese dal dataset di JD.com). Dipendentemente dalla qualità dell’immagine il bot:
- Riconosce la presenza di un oggetto e, in base a delle probabilità calcolate su ognuna delle tre macro-categorie, segnala all’utente se appartiene o meno.
- Propone all’utente un miglioramento ad esempio sulla luminosità, questo grazie agli script di correzione implementati.